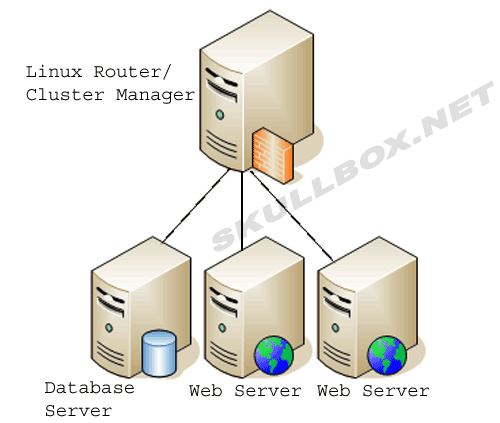
Cluster [ Server ]
Um
cluster, ou
aglomerado de computadores, é formado por um conjunto de computadores, que utiliza-se de um tipo especial de sistema operacional classificado como sistema distribuído. É construído muitas vezes a partir de computadores convencionais (desktops), sendo que estes vários computadores são ligados em rede e comunicam-se através do sistema de forma que trabalham como se fosse uma única máquina de grande porte. Há diversos tipos de cluster: o cluster Beowulf é constituido por diversos nós escravos gerenciados por um só computador.
História
A idéia inicial que conduz ao cluster foi desenvolvida na década de 1960 pela IBM como uma forma de interligar grandes mainframes, visando obter uma solução comercialmente viável de paralelismo. Nesta época o sistema HASP (Houston Automatic Spooling Priority) da IBM e seu sucessor, JES (Job Entry System) proviam uma maneira de distribuir tarefas nos mainframes interligados. A IBM ainda hoje (2001) suporta o cluster de mainframes através do Parallel Sysplex System, que permite que ao hardware, sistema operacional, middleware, e o software de gerenciamento do sistema prover uma melhora dramática na performance e custo ao permitir que usuários da grandes mainframes continuem utilizando suas aplicações existentes.
Entretanto, o cluster ganhou força até que três tendências convergiram nos anos 1980: microprocessadores de alta performance, redes de alta velocidade, e ferramentas padronizadas para computação distribuída de alto desempenho. Uma quarta tendência possível é a crescente necessidade de poder de processamento para aplicações científicas e comerciais unida ao alto custo e a baixa acessibilidade dos tradicionais dos supercomputadores.
No final de 1993, Donald Becker e Thomas Sterling iniciaram um esboço de um sistema de processamento distribuído construído a partir de hardware convencional como uma medida de combate aos custos dos supercomputadores. No início de 1994, trabalhando no CESDIS, com o patrocínio do projecto HTPCC/ESS, nasce o primeiro cluster e, consequentemente, o projecto Beowulf.
O protótipo inicial era um cluster de 16 processadores DX4 ligados por dois canais Ethernet acoplados (Ethernet bonding). A máquina foi um sucesso instantâneo, e esta idéia rapidamente se espalhou pelos meios académicos e pela NASA e outras comunidades de pesquisa.
Tipos de cluster
Cluster de Alto Desempenho: Também conhecido como cluster de alta performance ele funciona permitindo que ocorra uma grande carga de processamento com um volume alto de gigaflops em computadores comuns e utilizando sistema operacional gratuito o que diminui seu custo.
Cluster de Alta Disponibilidade: São clusters os quais seus sistemas conseguem permanecer ativos por um longo período de tempo e em plena condição de uso sendo assim podemos dizer que eles nunca param seu funcionamento, além disso, conseguem detectar erros se protegendo de possíveis falhas.
Cluster para Balanceamento de Carga: Esse tipo de cluster tem como função controlar a distribuição equilibrada do processamento. Requer um monitoramento constante na sua comunicação e em seus mecanismos de redundância, pois se ocorrer alguma falha haverá uma interrupção no seu funcionamento.
Sistema de processamento distribuído
Um sistema de processamento distribuído ou paralelo é um sistema que interliga vários nós de processamento (computadores individuais, não necessariamente homogéneos) de maneira que um processo de grande consumo seja executado no nó "mais disponível", ou mesmo subdividido por vários nós. Adivinham-se, portanto, ganhos óbvios nestas soluções: uma tarefa qualquer, se divisível em várias subtarefas pode ser realizada em paralelo.
A nomenclatura geralmente utilizada neste contexto é HPC (High Performance Computing) e/ou DPC (Distributed/Parallel Computing).
Desenvolvimento
Este é um assunto muito vasto e, embora com alguma idade, só agora (~2001) se começa a falar em standards para estas soluções, que são utilizadas (em larga escala) geralmente nos meios científicos e outros de cálculo intensivo pela sua extensibilidade. São bastante flexíveis, já que permitem a coexistência de sistemas desenhados especificamente para isso (por exemplo, a arquitectura NUMA), de sistemas desktop, e mesmo de sistemas considerados obsoletos, mas não o suficiente para permitir a coexistência de soluções semelhantes.
Antes de avançar, será necessário distinguir um sistema de multiprocessamento paralelo (SMP) de um sistema distribuído. Para um sistema ser de processamento distribuído, uma ou várias unidades de processamento (CPU) estará separada fisicamente da(s) outra(s), enquanto que num sistema SMP todas as unidades de processamento se encontram na mesma máquina. Ambos sistemas são capazes de processamento paralelo, e qualquer um deles pode ser visto como elemento de um sistema distribuído!
Com os desenvolvimentos nesta área, surgiram soluções por software que fazem, geralmente (mas não necessariamente), alterações no núcleo do sistema operativo e que, na maioria dos casos, não são compatíveis entre elas, e dificilmente entre versões diferentes da mesma solução. Assentam, no entanto, em arquitecturas de comunicação standard, como é o caso da Parallel Virtual Machine e Message Passing Interface. Resumidamente, estas arquitecturas conseguem transportar um processo (tarefa) e o seu contexto (ficheiros abertos, etc.) pela rede até outro nó. O nó que originou o processo passa, assim, a ser apenas um receptor dos resultados desse processo.
Actualmente, a principal barreira destes sistemas é implementar mecanismos de Inter-Process Communication (IPC), os Distributed IPC, dada a sua extrema complexidade.
Arquitectura
A Figura 1 ilustra as várias camadas de interoperabilidade de um sistema distribuído. Através do gateway a rede pública tem acesso a um supercomputador, sem ter conhecimento disso, dado que só conhece o gateway. Qualquer aplicação executada no gateway (preparada para ser parelelizada) pode ser distribuída por vários nós, entregando os resultados mais rápido que se fosse processada apenas por um único nó.
Computação distribuída
A computação distribuída, ou sistema distribuído, é uma referência à computação paralela e descentralizada, realizada por dois ou mais computadores conectados através de uma rede, cujo objetivo é concluir uma tarefa em comum.
Definição
Um sistema distribuído segundo a definição de Andrew Tanenbaum é uma "coleção de computadores independentes que se apresenta ao usuário como um sistema único e consistente"[1]; outra definição, de George Coulouris, diz: "coleção de computadores autônomos interligados através de uma rede de computadores e equipados com software que permita o compartilhamento dos recursos do sistema: hardware, software e dados"[Necessita de fonte].
Assim, a computação distribuída consiste em adicionar o poder computacional de diversos computadores interligados por uma rede de computadores ou mais de um processador trabalhando em conjunto no mesmo computador, para processar colaborativamente determinada tarefa de forma coerente e transparente, ou seja, como se apenas um único e centralizado computador estivesse executando a tarefa. A união desses diversos computadores com o objetivo de compartilhar a execução de tarefas, é conhecida como sistema distribuído.
Organização
Organizar a interação entre cada computador é primordial. Visando poder usar o maior número possível de máquinas e tipos de computadores, o protocolo ou canal de comunicação não pode conter ou usar nenhuma informação que possa não ser entendida por certas máquinas. Cuidado especiais também devem ser tomado para que as mensagens sejam entregues corretamente e que as mensagens inválidas sejam rejeitadas, caso contrário, levaria o sistema a cair ou até o resto da rede.
Outro fator de importância é a habilidade de mandar softwares para outros computadores de uma maneira portável de tal forma que ele possa executar e interagir com a rede existente. Isso pode não ser possível ou prático quando usando hardware e recursos diferentes, onde cada caso deve ser tratado separadamente com cross-compiling ou reescrevendo software.
Modelos de computação distribuída
Cliente/Servidor
O cliente manda um pedido para o servidor e o servidor o retorna.
Peer-to-peer (P2P)
O banco de dados manda um pedido para o gerenciador, o gerenciador retorna para o banco de dados e pede confirmação, e o banco de dados retorna para o gerenciador.
Hardware
organização do hardware em sistemas com várias UCPs se dá por:
Sistemas paralelos
* É constituído de vários processadores tipicamente homogêneos e localizados em um mesmo computador.
* Multicomputadores - Cada processador possui sua própria memória local.
* Multiprocessadores - Os processadores compartilham memória.
Arquiteturas
* Multiprocessadores em barramento.
* Multiprocessador.
* Multiprocessador homogêneo.
* Multiprocessador heterogêneo.
Software
* Fracamente acoplados - permitem que máquinas e usuários de um sistema distribuído sejam fundamentalmente independentes e ainda interagir de forma limitada quando isto for necessário, compartilhando discos, impressoras e outros recursos.
* Fortemente acoplados - provê um nível de integração e compartilhamento de recursos mais intenso e transparente ao usuário caracterizando sistemas operacionais distribuídos.
Sistemas operacionais
* SO é um software que serve de interface entre o computador(Hardware)e nos humanos, ele permite
a execução de diversos outros softwares (aplicativos).
* SO de máquinas monoprocessadas.
* SO Multiprocessadores é uma extensão de SOs de máquinas monoprocessadas, a principal diferença sendo que os dados da memória são acessados por vários processadores e, portanto, necessitam de proteção com relação aos acessos concorrentes.
* SOs Multicomputadores são uma alternativas para o buffering de mensagens e pontos de bloqueio, alguns SOs disponibilizam uma abstração de memória compartilhada.
* SOs de rede: existe uma independência entre os computadores.
Sistemas fortemente acoplados Neste sistema existe vários processadores compartilhando uma memória, e gerenciado por apenas um S.O.
Multiplos processadores permite que vários programas sejam executados ao mesmo tempo em tempo real.Com isso será possível aumentar a capacidade de computação adicionando apenas processadores e.
Exemplos
* os sistemas operacionais mais conhecidos hoje são: Windows XP, Linux,Tiger(Apple).
* Um exemplo clássico de computação distribuída é o projeto Seti at home que visa procurar em sinais de rádio interplanetários algum vestígio de vida extraterrestre.
* O exemplo mais moderno desse paradigma é o BOINC, que é um framework de grade computacional no qual diversos projetos podem rodar suas aplicações, como fazem os projetos SETI@Home, ClimatePrediction.net, Einstein@Home e PrimeGrid.
Fotos de server em cluster:
Por: fUm4c1nH4_roo
Fonte: fUm4c1nh4_roo