provavelmente as duas vao anunciar suas intermediárias la... talvez 2 ou 3 de cada marcaDia 12 é a CES? Será que a Nvidia vai apresentar algo tbm?
-
Prezados usuários,
Por questões de segurança, a partir de 22/04/2024 os usuários só conseguirão logar no fórum se estiverem com a "Verificação em duas etapas" habilitada em seu perfil.
Para habilitar a "Verificação em duas etapas" entre em sua conta e "Click" em seu nick name na parte superior da página, aparecerá opções de gestão de sua conta, entre em "Senha e segurança", a primeira opção será para habilitar a "Verificação em duas etapas".
Clicando alí vai pedir a sua senha de acesso ao fórum, e depois vai para as opções de verificação, que serão as seguintes:
***Código de verificação via aplicativo*** >>>Isso permite que você gere um código de verificação usando um aplicativo em seu telefone.
***Email de confirmação*** >>>Isso enviará um código por e-mail para verificar seu login.
***Códigos alternativos*** >>>Esses códigos podem ser usados para fazer login se você não tiver acesso a outros métodos de verificação.
Existe as 3 opções acima, e para continuar acessando o fórum a partir de 22/04/2024 você deverá habilitar uma das 03 opções.
Tópico para tirar dúvidas>>>>https://forum.adrenaline.com.br/threads/obrigatoriedade-da-verificacao-em-duas-etapas-a-partir-de-24-04-2024-duvidas.712290/
Atencionamente,
Administração do Fórum Adrenaline
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
[TÓPICO DEDICADO] NAVI - próxima geração de GPUs da AMD
- Iniciador de Tópicos brender
- Data de Início

Sim, essas limitações de vBIOS acabam com as possibilidades da placa, ir até 2.8GHz e limitar o PL para não alcançar a 6900XT foi sacanagem =SConclusão:
Pró: Obtive resultados excelente e o modelo de referência extraiu o melhor do Chip dentro do que é possível nesse momento com bastante silêncio ainda.
Contra: A AMD claramente colocou um coleira no seus "Chip" da Navi2.
Só algumas poucas, mas o básico continua o mesmo:@dayllann sabe de mais informações novas das 6700/XT? Ou por enquanto, só aquelas que vc já tinha falado anteriormente? Estou aguardando a AMD e os refresh da Nvidia (que vc comentou no outro tópico) para decidir kkkkk Bem que os estoques de 6800 poderiam normalizar logo, tbm
- RX 6700XT terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho 20~25% melhor que a 5700XT, com o preço vazado de 350 dólares;
- RX 6700 terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho igual à 5700XT, com preço vazado de 300 dólares.
O que de novo tenho? O quanto o InfinityCache impactará em desempenho nas placas abaixo da Navi21, e como ele funciona internamente. Deixei um comentário em uma notícia lá do portal com uma síntese do conteúdo, mas aqui dá para escrever de forma mais completa :3

GeForce RTX 3050 4GB, RTX 3050 Ti 6GB e RTX 3060 12GB aparecem em listagem da Lenovo
Novas placas de vídeo da NVIDIA devem ser apresentadas no começo de 2021 como opções para o segmento intermediário
 adrenaline.com.br
adrenaline.com.br

Esse gráfico auxiliará a entender os números: Veja que nele há três marcações com 'X', e são nos valores de 128MB, 96MB e 64MB. Por quê? Ao que tudo indica estas são as quantidades de InfCache das Navi21 (6800/6900), Navi22 (6700) e Navi23 (6600), respectivamente. Sabemos que quanto maior a resolução maior a necessidade de largura de banda, mas isso não significa que resoluções menores não se beneficiem com largura extra, e é justamente isso que vemos com a 6800XT em 1080p e 1440p.
Para saber o quanto o tamanho ajuda em qual resolução, eis aqui um gráfico (velocidade média usada nos cálculos = 1,94GHz):
| Tamanho do IC | Bandwidth do IC | Hitrate em 1080p | Hitrate em 1440p | Hitrate em 2160p |
|---|---|---|---|---|
| 16MB | 248GB/s | 37% | 25% | 17% |
| 24MB | 373GB/s | 48% | 31% | 24% |
| 32MB | 497GB/s | 55% | 39% | 26% |
| 48MB | 745GB/s | 66% | 49% | 34% |
| 64MB | 993GB/s | 72% | 59% | 41% |
| 96MB | 1490GB/s | 78% | 66% | 52% |
| 128MB | 1987GB/s | 81% | 74% | 58% |
Vejam as taxas de acerto: Qualquer valor acima de 50% está bom, e acima de 75% está ótimo. Aqui quanto maior a porcentagem menos as unidades computacionais acessarão diretamente a VRAM em sua velocidade limitada (512GB/s na Navi21, 384GB/s na Navi22 e 256GB/s na Navi23), e isso deixa claro o foco de cada chip se levarmos em consideração a palavra da AMD de que 128MB mira em 4K, que seria 1440p na Navi22 e 1080p na Navi23. "Ah Dayllann, a 6800XT não se dá tão bem assim em 4K não, falta largura de banda", ok, concordo até certo ponto e basta olhar a tava de acerto nessa resolução para entender o porquê: Mesmo a GPU conseguindo acessar os dados a quase 2TB/s, apenas 58% das vezes os dados estão lá, os outros 42% precisam ser puxados a 512GB/s, então por mais que o IC ajude essa taxa de acerto está muito baixa. No gráfico vemos que a resolução 4K ainda estava em crescimento acelerado ao passar dos 140MB, então se fossem 256MB o hitrate nessa resolução estaria em ~75% e o desempenho da 6800XT, por exemplo, em 4K seria o equivalente ao que ela performa hoje em 1440p (considerando que falta apenas largura de banda para tal).
Claro que não é apenas hitrate que muda quando alteramos a quantidade de IC, a velocidade média dela também, pois cada Megabyte do IC se comunica a uma largura equivalente a um barramento de 64bits. Isso entrega 8192bits no IC da Navi21, 6144bits no IC da Navi22 e 4096bits no IC da Navi23 (e um possível 2048bits na futura Navi24, caso ela tenha IC). Agora é só calcular a largura efetiva (bwIC*hit+bwVRAM) em cada resolução e... já fiz isso, eis abaixo a conclusão:
| GPU | Hierarq. Mem. | BW Real | BW Efetivo FHD | BW Efetivo 2K | BW Efetivo 4K | Classificação |
|---|---|---|---|---|---|---|
| 6800XT | 128MB @8192bits + 16GB @256bits | 512GB/s | 2121GB/s | 1982GB/s | 1664GB/s | Excepcional em FHD, ótima em 2K, boa em 4K |
| 6700XT | 96MB @6144bits + 12GB @192bits | 384GB/s | 1546GB/s | 1367GB/s | 1159GB/s | Excelente em FHD, muito boa em 2K, arrisca 4K |
| 6600XT | 64MB @4096bits + 8GB @128bits | 256GB/s | 970GB/s | 842GB/s | 663GB/s | Ótima em FHD, boa em 2K, evite 4K |
| 6500XT | 32MB @2048bits + 4GB @64bits | 128GB/s | 401GB/s | 322GB/s | 257GB/s | Boa em FHD, evite 2K, sem chances de 4K |
[Legenda Classificação: Excepcional > Excelente > Ótimo > Muito bom > Bom > Arrisca > Evite > Sem chance]
Vale lembrar que para este cálculo eu considerei que 1) todas estas placas utilizam memórias GDDR6 à 16Gbps e 2) que o clock médio de todas estas placas será de 1,94GHz (provavelmente não, visto que as Navi23 e Navi24 não alcançarão 2.8GHz de boost). Agora se me permitem ir mais longe... e se a AMD colocar InfinityCache nas APUs com RDNA2?
Vejam, o Renoir mede um total de 156mm² e é Zen2+Vega, enquanto que o Rembrandt já se sabe que será Zen3+RDNA2 em um tamanho de 208mm². Mantendo a mesma quantidade de núcleos e ter o dobro de cache L3 não deveria aumentar tanto assim seu tamanho, até porque a densidade será maior (7nm -> 6nm), então o que estaria aumentando tanto o tamanho desse die além dos núcleos RDNA2? Aqui é que entra a especulação de InfinityCache nas APUs

Se isso proceder o ganho em desempenho nessas iGPUs será enorme, justamente por que hoje em dia o que segura o desempenho delas é a largura de banda baixa das memórias DDR4 (o Renoir mesmo, entrega 51,2GB/s com memórias DDR4-3200 para sua Vega8). Exemplificando: O Rembrandt terá suporte para memórias DDR5-5200 e/ou LPDDR5-6400, então usando o primeiro caso temos ((5200*128/8)*1,36) 113GB/s, o que é um baita ganho mas muito pouco para render bem em 1080p (uma GPU dedicada GDDR6 16Gbps @64bits oferece 128GB/s). Se colocarmos 16MB de InfinityCache nessa APU (o que deve ocupar ~9mm² de todo o die em 6nm) essa largura aumenta para efetivos (248*0,37+113) ~205GB/s, já se for 24MB (~13mm²) teremos um efetivo de 292GB/s e se arriscarmos 32MB (~18mm²) teremos um efetivo de 386GB/s! Este segundo caso é um perfeito sweet-spot e renderia igual a uma GPU dedicada GDDR6 16Gbps @128bits.
Só falta agora sabermos quantos CUs terá o Rembrandt, porque os 6nm permitem uma densidade 18% maior, logo se fosse Vega ele teria o tamanho de 128mm² e isso significa que temos 80mm² ai extras sem motivo aparente, então espero uns 16CUs com 24MB de InfinityCache na versão top desse danado, com desempenho de RX570 xD
Última edição:
@dayllann , comenta sobre o outro post que marquei você. Gostaria de saber sua opinião sobre a nova patente da AMD.Sim, essas limitações de vBIOS acabam com as possibilidades da placa, ir até 2.8GHz e limitar o PL para não alcançar a 6900XT foi sacanagem =S
Só algumas poucas, mas o básico continua o mesmo:
- RX 6700XT terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho 20~25% melhor que a 5700XT, com o preço vazado de 350 dólares;
- RX 6700 terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho igual à 5700XT, com preço vazado de 300 dólares.
O que de novo tenho? O quanto o InfinityCache impactará em desempenho nas placas abaixo da Navi21, e como ele funciona internamente. Deixei um comentário em uma notícia lá do portal com uma síntese do conteúdo, mas aqui dá para escrever de forma mais completa :3
GeForce RTX 3050 4GB, RTX 3050 Ti 6GB e RTX 3060 12GB aparecem em listagem da Lenovo
Novas placas de vídeo da NVIDIA devem ser apresentadas no começo de 2021 como opções para o segmento intermediário
Esse gráfico auxiliará a entender os números: Veja que nele há três marcações com 'X', e são nos valores de 128MB, 96MB e 64MB. Por quê? Ao que tudo indica estas são as quantidades de InfCache das Navi21 (6800/6900), Navi22 (6700) e Navi23 (6600), respectivamente. Sabemos que quanto maior a resolução maior a necessidade de largura de banda, mas isso não significa que resoluções menores não se beneficiem com largura extra, e é justamente isso que vemos com a 6800XT em 1080p e 1440p.
Para saber o quanto o tamanho ajuda em qual resolução, eis aqui um gráfico (velocidade média usada nos cálculos = 1,94GHz):
Tamanho do IC Bandwidth do IC Hitrate em 1080p Hitrate em 1440p Hitrate em 2160p 16MB 248GB/s 37% 25% 17% 24MB 373GB/s 48% 31% 24% 32MB 497GB/s 55% 39% 26% 48MB 745GB/s 66% 49% 34% 64MB 993GB/s 72% 59% 41% 96MB 1490GB/s 78% 66% 52% 128MB 1987GB/s 81% 74% 58%
Vejam as taxas de acerto: Qualquer valor acima de 50% está bom, e acima de 75% está ótimo. Aqui quanto maior a porcentagem menos as unidades computacionais acessarão diretamente a VRAM em sua velocidade limitada (512GB/s na Navi21, 384GB/s na Navi22 e 256GB/s na Navi23), e isso deixa claro o foco de cada chip se levarmos em consideração a palavra da AMD de que 128MB mira em 4K, que seria 1440p na Navi22 e 1080p na Navi23. "Ah Dayllann, a 6800XT não se dá tão bem assim em 4K não, falta largura de banda", ok, concordo até certo ponto e basta olhar a tava de acerto nessa resolução para entender o porquê: Mesmo a GPU conseguindo acessar os dados a quase 2TB/s, apenas 58% das vezes os dados estão lá, os outros 42% precisam ser puxados a 512GB/s, então por mais que o IC ajude essa taxa de acerto está muito baixa. No gráfico vemos que a resolução 4K ainda estava em crescimento acelerado ao passar dos 140MB, então se fossem 256MB o hitrate nessa resolução estaria em ~75% e o desempenho da 6800XT, por exemplo, em 4K seria o equivalente ao que ela performa hoje em 1440p (considerando que falta apenas largura de banda para tal).
Claro que não é apenas hitrate que muda quando alteramos a quantidade de IC, a velocidade média dela também, pois cada Megabyte do IC se comunica a uma largura equivalente a um barramento de 64bits. Isso entrega 8192bits no IC da Navi21, 6144bits no IC da Navi22 e 4096bits no IC da Navi23 (e um possível 2048bits na futura Navi24, caso ela tenha IC). Agora é só calcular a largura efetiva (bwIC*hit+bwVRAM) em cada resolução e... já fiz isso, eis abaixo a conclusão:
GPU Hierarq. Mem. BW Real BW Efetivo FHD BW Efetivo 2K BW Efetivo 4K Classificação 6800XT 128MB @8192bits + 16GB @256bits 512GB/s 2121GB/s 1982GB/s 1664GB/s Excepcional em FHD, ótima em 2K, boa em 4K 6700XT 96MB @6144bits + 12GB @192bits 384GB/s 1546GB/s 1367GB/s 1159GB/s Excelente em FHD, muito boa em 2K, arrisca 4K 6600XT 64MB @4096bits + 8GB @128bits 256GB/s 970GB/s 842GB/s 663GB/s Ótima em FHD, boa em 2K, evite 4K 6500XT 32MB @2048bits + 4GB @64bits 128GB/s 401GB/s 322GB/s 257GB/s Boa em FHD, evite 2K, sem chances de 4K [Legenda Classificação: Excepcional > Excelente > Ótimo > Muito bom > Bom > Arrisca > Evite > Sem chance]
Vale lembrar que para este cálculo eu considerei que 1) todas estas placas utilizam memórias GDDR6 à 16Gbps e 2) que o clock médio de todas estas placas será de 1,94GHz (provavelmente não, visto que as Navi23 e Navi24 não alcançarão 2.8GHz de boost). Agora se me permitem ir mais longe... e se a AMD colocar InfinityCache nas APUs com RDNA2?
Vejam, o Renoir mede um total de 156mm² e é Zen2+Vega, enquanto que o Rembrandt já se sabe que será Zen3+RDNA2 em um tamanho de 208mm². Mantendo a mesma quantidade de núcleos e ter o dobro de cache L3 não deveria aumentar tanto assim seu tamanho, até porque a densidade será maior (7nm -> 6nm), então o que estaria aumentando tanto o tamanho desse die além dos núcleos RDNA2? Aqui é que entra a especulação de InfinityCache nas APUs
Se isso proceder o ganho em desempenho nessas iGPUs será enorme, justamente por que hoje em dia o que segura o desempenho delas é a largura de banda baixa das memórias DDR4 (o Renoir mesmo, entrega 51,2GB/s com memórias DDR4-3200 para sua Vega8). Exemplificando: O Rembrandt terá suporte para memórias DDR5-5200 e/ou LPDDR5-6400, então usando o primeiro caso temos ((5200*128/8)*1,36) 113GB/s, o que é um baita ganho mas muito pouco para render bem em 1080p (uma GPU dedicada GDDR6 16Gbps @64bits oferece 128GB/s). Se colocarmos 16MB de InfinityCache nessa APU (o que deve ocupar ~13mm² de todo o die em 6nm) essa largura aumenta para efetivos (248*0,37+113) ~205GB/s, já se for 24MB (~20mm²) teremos um efetivo de 292GB/s e se arriscarmos 32MB (~26mm²) teremos um efetivo de 386GB/s! Este segundo caso é um perfeito sweet-spot e renderia igual a uma GPU dedicada GDDR6 16Gbps @128bits.
Só falta agora sabermos quantos CUs terá o Rembrandt, porque os 6nm permitem uma densidade 18% maior, logo se fosse Vega ele teria o tamanho de 128mm² e isso significa que temos 80mm² ai extras sem motivo aparente, então espero uns 16CUs com 24MB de InfinityCache na versão top desse danado, com desempenho de RX570 xD
Desculpe não ter respondido antes, é que passei um bom tempo elaborando a resposta do Infinity Cache... >.<@dayllann , você tinha visto isso aqui?
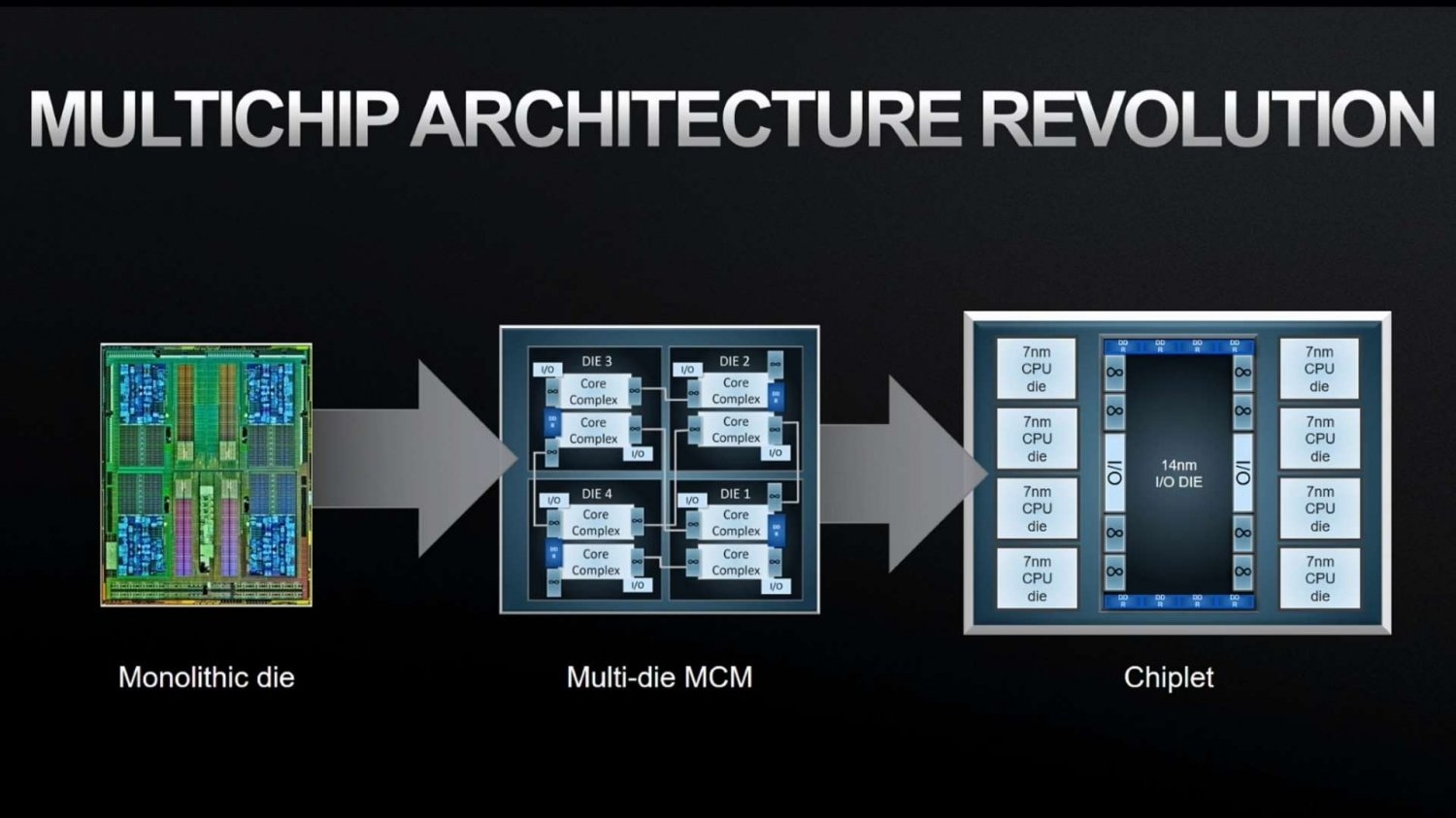
AMD patent teases GPU chiplet tech, the great big leap over NVIDIA?!
AMD submits GPU chiplet design patent to USPTO on December 31 that teases the future of GPU technology, an NVIDIA destroyer.www.tweaktown.com
... e precisei ler a patente, é claro :3
Mas vamos lá: TL/DR = Amei a patente, ela resolve o problema dos programas em reconhecer duas ou mais GPUs permitindo que apenas um chiplet se comunique com o CPU/driver e todos os demais chiplets se comuniquem apenas com o principal (estes serão invisíveis para o CPU/driver), e a intercomunicação que é o maior problema será realizada de forma passiva com coerência de caches (provavelmente um InfCache em cada chiplet) através de um link HBX que trafega dados por um interposer de alta velocidade (e não no substrato, como é feito nos CPUs Ryzen).
Agora vamos nos aprofundar nos como e por quê? Me conhecendo saberia que não iria parar em apenas quatro linhas, não é xD
Se você deu uma conferida na patente vai ver que constantemente é ressaltado o fato desse crosslink ser passivo, e isso é muito importante porque a intercomunicação é o que custa mais em questão de consumo e temperatura nessas abordagens (um Ryzen 3000 deveria consumir apenas 5W em idle, mas consome 15W por causa do IF ativo na proporão 1:1, o cIOD nunca para, tanto que nos Ryzen 4000 o consumo é infinitamente menor por ele ser monolítico).
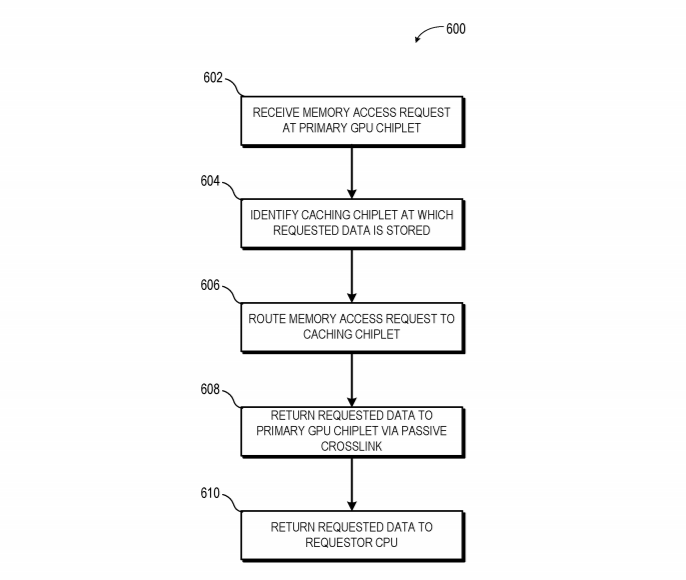
Voltando, a coerência aqui é muito importante, pois GPUs são massivamente paralelas ao mesmo tempo que processam muitos dados de forma serial, então é fundamental que cada um dos núcleos (5120 no caso da 6900XT) saiba o que os seus vizinhos estão e como estão fazendo seu trabalho, então o último nível da cache (chamaremos de LLC, para não atribuir um número) é sempre coerente por toda a GPU, e se eu ter mais de uma GPU realizando a mesma tarefa eu preciso que este LLC de ambas estejam "sincronizados", ou seja, um saiba o que o outro tem e se eu realizar alguma alteração em um o outro saiba o mais rápido possível sem precisar ser um clone do seu amigo (chamamos isso de coerência de dados).
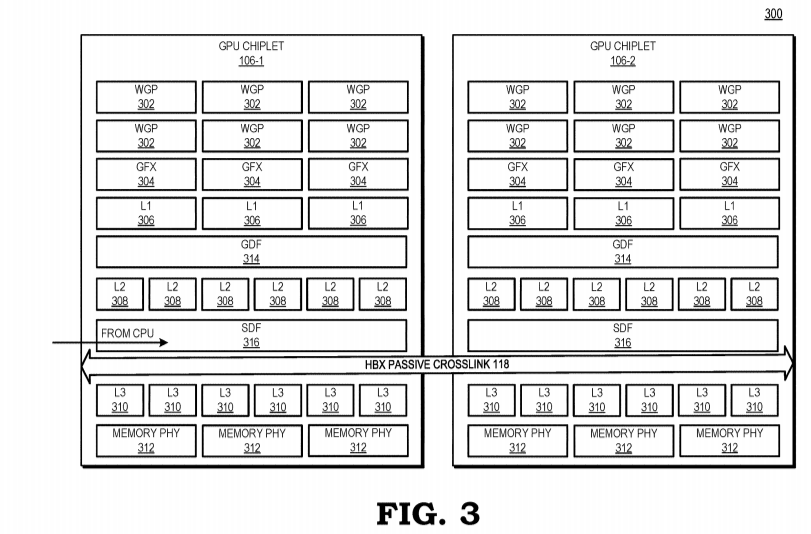
Então essa proposta de intercomunicação passiva através de um interposer (HBX) é boa mas complexa, já falei bastante (mal) sobre interposers e eles são um dos principais motivos para o HBM não ter um custo mais acessível, então esse HBX deve usar uma forma nova de interposer para ser considerável viável na patente, inclusive é citado que este interposer não usa TSVs para sua comunicação (usa RDL, e só isso já barateia bastante o sistema) mas somente isso não resolveria o problema, o S.O. ainda estará enxergando a GPU como mais de uma, mas o que a AMD fez foi criar um sistema invisível de chiplets, o qual apenas um deles é visível para o driver e os demais só se comunicam com o chiplet um, logo internamente a GPU opera de forma MCM mas externamente (aka, softwares) o sistema é visto como uma GPU monolítica. Basicamente, para quem é do tempo dos drivers IDE, a AMD criou um sistema Master/Slave interno
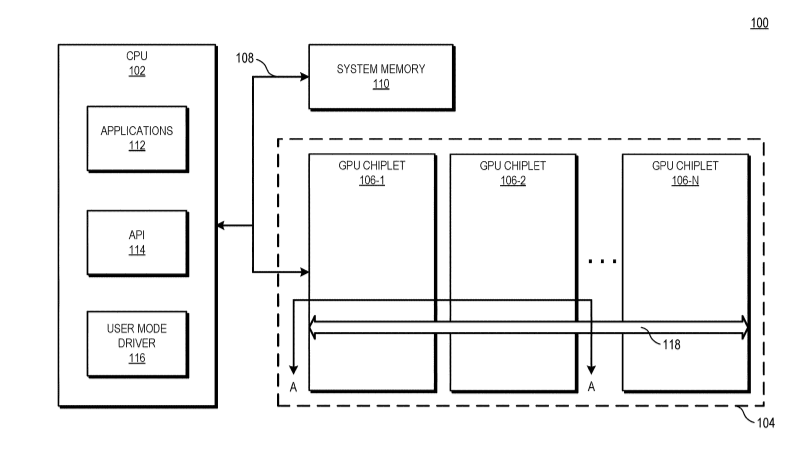
As caches L2 seriam coerentes com o chiplet, e a LLC seria coerente com todos os chiplets, então ela necessitaria ser grande o suficiente para funcionar como um buffer e cache ao mesmo tempo. Para amenizar qualquer ganho de latência todas as caches L1 estarão conectadas a um GDF (Graphics Data Fabric), permitindo que um bloco de cache L2 possa acessar qualquer cache L1 (já falei dessa patente aqui, um sistema de anel das cache L1 que permitiria que a caclhe local de um WGP seja acessada para leitura e escrita por outro WGP).
Um ponto negativo dessa abordagem é que, para cada chiplet a mais na GPU, mais controladores de intercomunicação (HBX PHY) serão necessários em cada chiplet (veja nas imagens, são quatro chiplets e em cada um deles temos quatro HBX PHY), aumentando o custo, tamanho e complexidade do die conforme for se acrescentando chiplets computacionais ao MCM. Sabendo disso já dá para ver possibilidades de melhorias! Essa forma de funcionar é exatamente igual a como os Threadripper de primeira geração se comunicavam, quatro dies cada um com seu I/O passando dados em forma cruzada entre eles, ao invés de ter um I/O centralizado, ou seja, essa segunda maneira pode ser o próximo passo a ser dado nesse MCM mas a dificuldade é muito maior dada a importância da latência em GPUs.
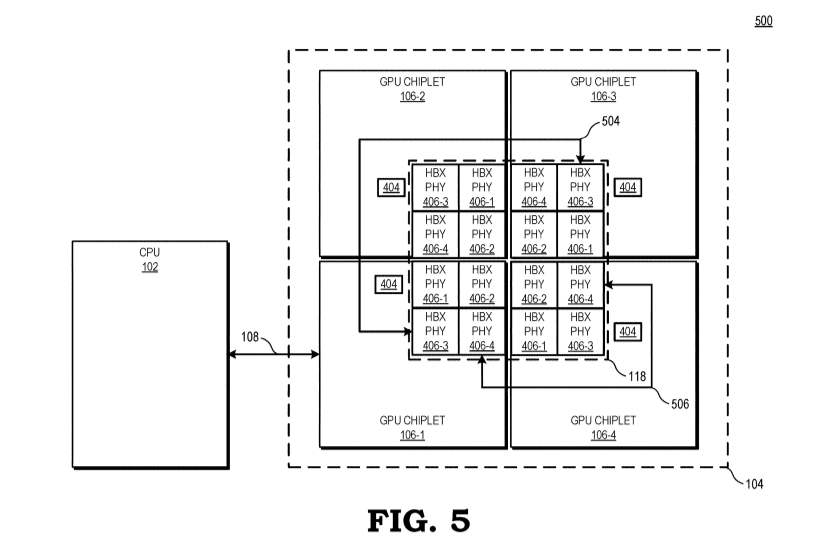
Dá para imaginar aqui um sistema futuro onde o I/O será um chiplet próprio e ele é que será o chiplet master, recebendo comandos do CPU e sincronizando as caches e funcionamento de demais chiplets ligados a ele através desses HBX... opa, me empolguei, mas é isso, espero que tenha deixado claro, mas qualquer coisa é só perguntar ^_^
PS1: Segundo a AMD esse acesso à / coerência da LLC em cada chiplet é feito de forma linear e por isso o tempo de acesso de uma cache L2 de um chiplet à cache L3 de outro chiplet (através do HBX) é praticamente o mesmo que se esse L2 requisitasse um dado da L2 do seu próprio chiplet.
PS2: O @igormp vai gostar desta outra patente aqui, que foi revelada ao mesmo tempo desta de GPUs MCM: FPGAs que reprogramam seu pipeline automaticamente de acordo com o batch a ser executado

A pergunta que fica é se a RDNA3 será baseada nesta patente ou é algo que será usado em algum produto que ainda será desenvolvimento.Desculpe não ter respondido antes, é que passei um bom tempo elaborando a resposta do Infinity Cache... >.<
... e precisei ler a patente, é claro :3
Mas vamos lá: TL/DR = Amei a patente, ela resolve o problema dos programas em reconhecer duas ou mais GPUs permitindo que apenas um chiplet se comunique com o CPU/driver e todos os demais chiplets se comuniquem apenas com o principal (estes serão invisíveis para o CPU/driver), e a intercomunicação que é o maior problema será realizada de forma passiva com coerência de caches (provavelmente um InfCache em cada chiplet) através de um link HBX que trafega dados por um interposer de alta velocidade (e não no substrato, como é feito nos CPUs Ryzen).
Agora vamos nos aprofundar nos como e por quê? Me conhecendo saberia que não iria parar em apenas quatro linhas, não é xD
Se você deu uma conferida na patente vai ver que constantemente é ressaltado o fato desse crosslink ser passivo, e isso é muito importante porque a intercomunicação é o que custa mais em questão de consumo e temperatura nessas abordagens (um Ryzen 3000 deveria consumir apenas 5W em idle, mas consome 15W por causa do IF ativo na proporão 1:1, o cIOD nunca para, tanto que nos Ryzen 4000 o consumo é infinitamente menor por ele ser monolítico).
Voltando, a coerência aqui é muito importante, pois GPUs são massivamente paralelas ao mesmo tempo que processam muitos dados de forma serial, então é fundamental que cada um dos núcleos (5120 no caso da 6900XT) saiba o que os seus vizinhos estão e como estão fazendo seu trabalho, então o último nível da cache (chamaremos de LLC, para não atribuir um número) é sempre coerente por toda a GPU, e se eu ter mais de uma GPU realizando a mesma tarefa eu preciso que este LLC de ambas estejam "sincronizados", ou seja, um saiba o que o outro tem e se eu realizar alguma alteração em um o outro saiba o mais rápido possível sem precisar ser um clone do seu amigo (chamamos isso de coerência de dados).
Então essa proposta de intercomunicação passiva através de um interposer (HBX) é boa mas complexa, já falei bastante (mal) sobre interposers e eles são um dos principais motivos para o HBM não ter um custo mais acessível, então esse HBX deve usar uma forma nova de interposer para ser considerável viável na patente, inclusive é citado que este interposer não usa TSVs para sua comunicação (usa RDL, e só isso já barateia bastante o sistema) mas somente isso não resolveria o problema, o S.O. ainda estará enxergando a GPU como mais de uma, mas o que a AMD fez foi criar um sistema invisível de chiplets, o qual apenas um deles é visível para o driver e os demais só se comunicam com o chiplet um, logo internamente a GPU opera de forma MCM mas externamente (aka, softwares) o sistema é visto como uma GPU monolítica. Basicamente, para quem é do tempo dos drivers IDE, a AMD criou um sistema Master/Slave interno
As caches L2 seriam coerentes com o chiplet, e a LLC seria coerente com todos os chiplets, então ela necessitaria ser grande o suficiente para funcionar como um buffer e cache ao mesmo tempo. Para amenizar qualquer ganho de latência todas as caches L1 estarão conectadas a um GDF (Graphics Data Fabric), permitindo que um bloco de cache L2 possa acessar qualquer cache L1 (já falei dessa patente aqui, um sistema de anel das cache L1 que permitiria que a caclhe local de um WGP seja acessada para leitura e escrita por outro WGP).
Um ponto negativo dessa abordagem é que, para cada chiplet a mais na GPU, mais controladores de intercomunicação (HBX PHY) serão necessários em cada chiplet (veja nas imagens, são quatro chiplets e em cada um deles temos quatro HBX PHY), aumentando o custo, tamanho e complexidade do die conforme for se acrescentando chiplets computacionais ao MCM. Sabendo disso já dá para ver possibilidades de melhorias! Essa forma de funcionar é exatamente igual a como os Threadripper de primeira geração se comunicavam, quatro dies cada um com seu I/O passando dados em forma cruzada entre eles, ao invés de ter um I/O centralizado, ou seja, essa segunda maneira pode ser o próximo passo a ser dado nesse MCM mas a dificuldade é muito maior dada a importância da latência em GPUs.
Dá para imaginar aqui um sistema futuro onde o I/O será um chiplet próprio e ele é que será o chiplet master, recebendo comandos do CPU e sincronizando as caches e funcionamento de demais chiplets ligados a ele através desses HBX... opa, me empolguei, mas é isso, espero que tenha deixado claro, mas qualquer coisa é só perguntar ^_^
PS1: Segundo a AMD esse acesso à / coerência da LLC em cada chiplet é feito de forma linear e por isso o tempo de acesso de uma cache L2 de um chiplet à cache L3 de outro chiplet (através do HBX) é praticamente o mesmo que se esse L2 requisitasse um dado da L2 do seu próprio chiplet.
PS2: O @igormp vai gostar desta outra patente aqui, que foi revelada ao mesmo tempo desta de GPUs MCM: FPGAs que reprogramam seu pipeline automaticamente de acordo com o batch a ser executado
Se a RDNA3 vir MCM, vai ser em cima dessa patente, este é o método mais funcional que vi até agora para abordar MCM em GPUs para jogos, o método da patente da NVIDIA é ótimo também mas para datacenters, não para joguinhos. E quanto a estar em desenvolvimento, normalmente a AMD torna pública suas patentes quando já tem algum hardware usando elas em laboratório, no caso ela cria a tecnologia e testa, se funcionar "lança" a patente dela para garantir que ninguém copiará igualA pergunta que fica é se a RDNA3 será baseada nesta patente ou é algo que será usado em algum produto que ainda será desenvolvimento.
Veja, antes da RDNA2 lançar foi que se tornou pública duas patentes, uma do InfinityCache e outra do Cache L1 em anel, e adivinha? A RDNA2 utilizou uma delas, a outra patente está incorporada dentro desta patente de MCM com o nome de GDF, então a probabilidade da RDNA3 ser da maneira dessa patente é bem grande
---
Antes que eu me esqueça, apareceu mais uma variante da Navi21, a XTXH, e apesar de não ter nenhuma informação além desse nome já estão especulando que se trata de uma "6900XT" com memórias HBM (seria então a 6950XT? 6900XTX? 6900 Pro???), e se isso for verdade é melhor a NVIDIA se segurar, porque esta placa vai mirar bem na RTX 3090 xD
AMEI. Será que a AMD vai conseguir emplacar uma CPU com FPGA no mesmo die? A tentativa da intel nisso creio que tenha sido um belo flop.PS2: O @igormp vai gostar desta outra patente aqui, que foi revelada ao mesmo tempo desta de GPUs MCM: FPGAs que reprogramam seu pipeline automaticamente de acordo com o batch a ser executado
Uma coisa que me deixou curioso foi que eles falaram que PCIe seria um gargalo, porém não citaram qual a alternativa (me corrija se estiver errado). Fiquei curioso para saber oq eles usariam pra comunicar algo de forma a ter latências aceitáveis. Pior ainda, me pergunto como fariam pra reprogramar de forma tão rápida após uma troca de contexto, já que normalmente é um processo lento.
Se isso der certo, acho que significaria a morte de toda a ideia de extensões de CPU, visto que vc poderia ter algo dinâmico e bem mais otimizado pra sua aplicação em específico (bem como ter mais de uma ativa ao mesmo tempo!!), sem falar que finalmente seria possível baixar mais ram assim xD
Gostei da patente (ia fazer uma tirada sobre banheiro, mas aqui é mais sério)!Desculpe não ter respondido antes, é que passei um bom tempo elaborando a resposta do Infinity Cache... >.<
... e precisei ler a patente, é claro :3
Mas vamos lá: TL/DR = Amei a patente, ela resolve o problema dos programas em reconhecer duas ou mais GPUs permitindo que apenas um chiplet se comunique com o CPU/driver e todos os demais chiplets se comuniquem apenas com o principal (estes serão invisíveis para o CPU/driver), e a intercomunicação que é o maior problema será realizada de forma passiva com coerência de caches (provavelmente um InfCache em cada chiplet) através de um link HBX que trafega dados por um interposer de alta velocidade (e não no substrato, como é feito nos CPUs Ryzen).
Agora vamos nos aprofundar nos como e por quê? Me conhecendo saberia que não iria parar em apenas quatro linhas, não é xD
Se você deu uma conferida na patente vai ver que constantemente é ressaltado o fato desse crosslink ser passivo, e isso é muito importante porque a intercomunicação é o que custa mais em questão de consumo e temperatura nessas abordagens (um Ryzen 3000 deveria consumir apenas 5W em idle, mas consome 15W por causa do IF ativo na proporão 1:1, o cIOD nunca para, tanto que nos Ryzen 4000 o consumo é infinitamente menor por ele ser monolítico).
Voltando, a coerência aqui é muito importante, pois GPUs são massivamente paralelas ao mesmo tempo que processam muitos dados de forma serial, então é fundamental que cada um dos núcleos (5120 no caso da 6900XT) saiba o que os seus vizinhos estão e como estão fazendo seu trabalho, então o último nível da cache (chamaremos de LLC, para não atribuir um número) é sempre coerente por toda a GPU, e se eu ter mais de uma GPU realizando a mesma tarefa eu preciso que este LLC de ambas estejam "sincronizados", ou seja, um saiba o que o outro tem e se eu realizar alguma alteração em um o outro saiba o mais rápido possível sem precisar ser um clone do seu amigo (chamamos isso de coerência de dados).
Então essa proposta de intercomunicação passiva através de um interposer (HBX) é boa mas complexa, já falei bastante (mal) sobre interposers e eles são um dos principais motivos para o HBM não ter um custo mais acessível, então esse HBX deve usar uma forma nova de interposer para ser considerável viável na patente, inclusive é citado que este interposer não usa TSVs para sua comunicação (usa RDL, e só isso já barateia bastante o sistema) mas somente isso não resolveria o problema, o S.O. ainda estará enxergando a GPU como mais de uma, mas o que a AMD fez foi criar um sistema invisível de chiplets, o qual apenas um deles é visível para o driver e os demais só se comunicam com o chiplet um, logo internamente a GPU opera de forma MCM mas externamente (aka, softwares) o sistema é visto como uma GPU monolítica. Basicamente, para quem é do tempo dos drivers IDE, a AMD criou um sistema Master/Slave interno
As caches L2 seriam coerentes com o chiplet, e a LLC seria coerente com todos os chiplets, então ela necessitaria ser grande o suficiente para funcionar como um buffer e cache ao mesmo tempo. Para amenizar qualquer ganho de latência todas as caches L1 estarão conectadas a um GDF (Graphics Data Fabric), permitindo que um bloco de cache L2 possa acessar qualquer cache L1 (já falei dessa patente aqui, um sistema de anel das cache L1 que permitiria que a caclhe local de um WGP seja acessada para leitura e escrita por outro WGP).
Um ponto negativo dessa abordagem é que, para cada chiplet a mais na GPU, mais controladores de intercomunicação (HBX PHY) serão necessários em cada chiplet (veja nas imagens, são quatro chiplets e em cada um deles temos quatro HBX PHY), aumentando o custo, tamanho e complexidade do die conforme for se acrescentando chiplets computacionais ao MCM. Sabendo disso já dá para ver possibilidades de melhorias! Essa forma de funcionar é exatamente igual a como os Threadripper de primeira geração se comunicavam, quatro dies cada um com seu I/O passando dados em forma cruzada entre eles, ao invés de ter um I/O centralizado, ou seja, essa segunda maneira pode ser o próximo passo a ser dado nesse MCM mas a dificuldade é muito maior dada a importância da latência em GPUs.
Dá para imaginar aqui um sistema futuro onde o I/O será um chiplet próprio e ele é que será o chiplet master, recebendo comandos do CPU e sincronizando as caches e funcionamento de demais chiplets ligados a ele através desses HBX... opa, me empolguei, mas é isso, espero que tenha deixado claro, mas qualquer coisa é só perguntar ^_^
PS1: Segundo a AMD esse acesso à / coerência da LLC em cada chiplet é feito de forma linear e por isso o tempo de acesso de uma cache L2 de um chiplet à cache L3 de outro chiplet (através do HBX) é praticamente o mesmo que se esse L2 requisitasse um dado da L2 do seu próprio chiplet.
PS2: O @igormp vai gostar desta outra patente aqui, que foi revelada ao mesmo tempo desta de GPUs MCM: FPGAs que reprogramam seu pipeline automaticamente de acordo com o batch a ser executado
Se essa Patente confirma que já existe Chiplets de GPU então outra Probilidade seria 2 Chiplets um encima do outra com 3D stacking via SoiC da Tsmc.

Será que virá com mais memória tbm? Além dos 16 GB da 6900 "normal"?Antes que eu me esqueça, apareceu mais uma variante da Navi21, a XTXH, e apesar de não ter nenhuma informação além desse nome já estão especulando que se trata de uma "6900XT" com memórias HBM (seria então a 6950XT? 6900XTX? 6900 Pro???), e se isso for verdade é melhor a NVIDIA se segurar, porque esta placa vai mirar bem na RTX 3090 xD
No site Wcctech foi explanado também sobre o ganho de aproveitamento do wafer que esta patente traria na fabricação de GPUs:Se a RDNA3 vir MCM, vai ser em cima dessa patente, este é o método mais funcional que vi até agora para abordar MCM em GPUs para jogos, o método da patente da NVIDIA é ótimo também mas para datacenters, não para joguinhos. E quanto a estar em desenvolvimento, normalmente a AMD torna pública suas patentes quando já tem algum hardware usando elas em laboratório, no caso ela cria a tecnologia e testa, se funcionar "lança" a patente dela para garantir que ninguém copiará igual
Veja, antes da RDNA2 lançar foi que se tornou pública duas patentes, uma do InfinityCache e outra do Cache L1 em anel, e adivinha? A RDNA2 utilizou uma delas, a outra patente está incorporada dentro desta patente de MCM com o nome de GDF, então a probabilidade da RDNA3 ser da maneira dessa patente é bem grande
---
Antes que eu me esqueça, apareceu mais uma variante da Navi21, a XTXH, e apesar de não ter nenhuma informação além desse nome já estão especulando que se trata de uma "6900XT" com memórias HBM (seria então a 6950XT? 6900XTX? 6900 Pro???), e se isso for verdade é melhor a NVIDIA se segurar, porque esta placa vai mirar bem na RTX 3090 xD

AMD Files MCM Based GPU Patent - Finally Bringing The MCM Approach To Radeon GPUs?
AMD has filed a patent for something that everyone knew would eventually happen: an MCM GPU Chiplet design. Spotted by LaFriteDavid over at Twitter and published on Freepatents.com, the document shows how AMD plans to build a GPU chiplet graphics card that is eerily reminiscent of its MCM based...
E sobre o novo chip NAVI, será que a AMD estaria preparando versões das placas usando memória HBM para concorrer com as futuras RTX 3000 Super? Ou então uma nova variante de GPU mais potente que a atual?
6700 não seria 10gb e 6700xt 12gb? Mesmo por 300$ vai ser um bom CxB...uma placa de 10/12gb por 300$ enquanto a 3060 6gb deve chegar por 300$ (ou mais até)Sim, essas limitações de vBIOS acabam com as possibilidades da placa, ir até 2.8GHz e limitar o PL para não alcançar a 6900XT foi sacanagem =S
Só algumas poucas, mas o básico continua o mesmo:
- RX 6700XT terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho 20~25% melhor que a 5700XT, com o preço vazado de 350 dólares;
- RX 6700 terá 12GB de memória, será 192bits com 96MB de InfinityCache e desempenho igual à 5700XT, com preço vazado de 300 dólares.
O que de novo tenho? O quanto o InfinityCache impactará em desempenho nas placas abaixo da Navi21, e como ele funciona internamente. Deixei um comentário em uma notícia lá do portal com uma síntese do conteúdo, mas aqui dá para escrever de forma mais completa :3
GeForce RTX 3050 4GB, RTX 3050 Ti 6GB e RTX 3060 12GB aparecem em listagem da Lenovo
Novas placas de vídeo da NVIDIA devem ser apresentadas no começo de 2021 como opções para o segmento intermediário
Esse gráfico auxiliará a entender os números: Veja que nele há três marcações com 'X', e são nos valores de 128MB, 96MB e 64MB. Por quê? Ao que tudo indica estas são as quantidades de InfCache das Navi21 (6800/6900), Navi22 (6700) e Navi23 (6600), respectivamente. Sabemos que quanto maior a resolução maior a necessidade de largura de banda, mas isso não significa que resoluções menores não se beneficiem com largura extra, e é justamente isso que vemos com a 6800XT em 1080p e 1440p.
Para saber o quanto o tamanho ajuda em qual resolução, eis aqui um gráfico (velocidade média usada nos cálculos = 1,94GHz):
Tamanho do IC Bandwidth do IC Hitrate em 1080p Hitrate em 1440p Hitrate em 2160p 16MB 248GB/s 37% 25% 17% 24MB 373GB/s 48% 31% 24% 32MB 497GB/s 55% 39% 26% 48MB 745GB/s 66% 49% 34% 64MB 993GB/s 72% 59% 41% 96MB 1490GB/s 78% 66% 52% 128MB 1987GB/s 81% 74% 58%
Vejam as taxas de acerto: Qualquer valor acima de 50% está bom, e acima de 75% está ótimo. Aqui quanto maior a porcentagem menos as unidades computacionais acessarão diretamente a VRAM em sua velocidade limitada (512GB/s na Navi21, 384GB/s na Navi22 e 256GB/s na Navi23), e isso deixa claro o foco de cada chip se levarmos em consideração a palavra da AMD de que 128MB mira em 4K, que seria 1440p na Navi22 e 1080p na Navi23. "Ah Dayllann, a 6800XT não se dá tão bem assim em 4K não, falta largura de banda", ok, concordo até certo ponto e basta olhar a tava de acerto nessa resolução para entender o porquê: Mesmo a GPU conseguindo acessar os dados a quase 2TB/s, apenas 58% das vezes os dados estão lá, os outros 42% precisam ser puxados a 512GB/s, então por mais que o IC ajude essa taxa de acerto está muito baixa. No gráfico vemos que a resolução 4K ainda estava em crescimento acelerado ao passar dos 140MB, então se fossem 256MB o hitrate nessa resolução estaria em ~75% e o desempenho da 6800XT, por exemplo, em 4K seria o equivalente ao que ela performa hoje em 1440p (considerando que falta apenas largura de banda para tal).
Claro que não é apenas hitrate que muda quando alteramos a quantidade de IC, a velocidade média dela também, pois cada Megabyte do IC se comunica a uma largura equivalente a um barramento de 64bits. Isso entrega 8192bits no IC da Navi21, 6144bits no IC da Navi22 e 4096bits no IC da Navi23 (e um possível 2048bits na futura Navi24, caso ela tenha IC). Agora é só calcular a largura efetiva (bwIC*hit+bwVRAM) em cada resolução e... já fiz isso, eis abaixo a conclusão:
GPU Hierarq. Mem. BW Real BW Efetivo FHD BW Efetivo 2K BW Efetivo 4K Classificação 6800XT 128MB @8192bits + 16GB @256bits 512GB/s 2121GB/s 1982GB/s 1664GB/s Excepcional em FHD, ótima em 2K, boa em 4K 6700XT 96MB @6144bits + 12GB @192bits 384GB/s 1546GB/s 1367GB/s 1159GB/s Excelente em FHD, muito boa em 2K, arrisca 4K 6600XT 64MB @4096bits + 8GB @128bits 256GB/s 970GB/s 842GB/s 663GB/s Ótima em FHD, boa em 2K, evite 4K 6500XT 32MB @2048bits + 4GB @64bits 128GB/s 401GB/s 322GB/s 257GB/s Boa em FHD, evite 2K, sem chances de 4K [Legenda Classificação: Excepcional > Excelente > Ótimo > Muito bom > Bom > Arrisca > Evite > Sem chance]
Vale lembrar que para este cálculo eu considerei que 1) todas estas placas utilizam memórias GDDR6 à 16Gbps e 2) que o clock médio de todas estas placas será de 1,94GHz (provavelmente não, visto que as Navi23 e Navi24 não alcançarão 2.8GHz de boost). Agora se me permitem ir mais longe... e se a AMD colocar InfinityCache nas APUs com RDNA2?
Vejam, o Renoir mede um total de 156mm² e é Zen2+Vega, enquanto que o Rembrandt já se sabe que será Zen3+RDNA2 em um tamanho de 208mm². Mantendo a mesma quantidade de núcleos e ter o dobro de cache L3 não deveria aumentar tanto assim seu tamanho, até porque a densidade será maior (7nm -> 6nm), então o que estaria aumentando tanto o tamanho desse die além dos núcleos RDNA2? Aqui é que entra a especulação de InfinityCache nas APUs
Se isso proceder o ganho em desempenho nessas iGPUs será enorme, justamente por que hoje em dia o que segura o desempenho delas é a largura de banda baixa das memórias DDR4 (o Renoir mesmo, entrega 51,2GB/s com memórias DDR4-3200 para sua Vega8). Exemplificando: O Rembrandt terá suporte para memórias DDR5-5200 e/ou LPDDR5-6400, então usando o primeiro caso temos ((5200*128/8)*1,36) 113GB/s, o que é um baita ganho mas muito pouco para render bem em 1080p (uma GPU dedicada GDDR6 16Gbps @64bits oferece 128GB/s). Se colocarmos 16MB de InfinityCache nessa APU (o que deve ocupar ~9mm² de todo o die em 6nm) essa largura aumenta para efetivos (248*0,37+113) ~205GB/s, já se for 24MB (~13mm²) teremos um efetivo de 292GB/s e se arriscarmos 32MB (~18mm²) teremos um efetivo de 386GB/s! Este segundo caso é um perfeito sweet-spot e renderia igual a uma GPU dedicada GDDR6 16Gbps @128bits.
Só falta agora sabermos quantos CUs terá o Rembrandt, porque os 6nm permitem uma densidade 18% maior, logo se fosse Vega ele teria o tamanho de 128mm² e isso significa que temos 80mm² ai extras sem motivo aparente, então espero uns 16CUs com 24MB de InfinityCache na versão top desse danado, com desempenho de RX570 xD
Rapaz, ao meu ver essa compra da Xilinx vai render muito melhor que a da Altera pela Intel, o InfinityFabric como intercomunicação de baixa latência e alta velocidade será uma combinação bem promissora para criar um XPU eficiente.AMEI. Será que a AMD vai conseguir emplacar uma CPU com FPGA no mesmo die? A tentativa da intel nisso creio que tenha sido um belo flop.
Uma coisa que me deixou curioso foi que eles falaram que PCIe seria um gargalo, porém não citaram qual a alternativa (me corrija se estiver errado). Fiquei curioso para saber oq eles usariam pra comunicar algo de forma a ter latências aceitáveis. Pior ainda, me pergunto como fariam pra reprogramar de forma tão rápida após uma troca de contexto, já que normalmente é um processo lento.
Se isso der certo, acho que significaria a morte de toda a ideia de extensões de CPU, visto que vc poderia ter algo dinâmico e bem mais otimizado pra sua aplicação em específico (bem como ter mais de uma ativa ao mesmo tempo!!), sem falar que finalmente seria possível baixar mais ram assim xD
Sim, falaram que o PCIe tem latência alta e não deram alternativa, então o que veio na cabeça foram duas possibilidades, uma comunicação diferente (como o NVLink ou CXL) ou esse FPGA em um interposer MCM como coprocessador se comunicando por InfinityFabric (ou o recém mostrado HBX), são as únicas possibilidades que uniriam velocidade acima e latência abaixo do que o PCI-express pode oferecer até sua 6ª geração.
Mas a pergunta que também estava na minha cabeça logo ao começar a ler a patente foi exatamente esta sua, "Como faria para reprogramar de forma tão rápida após uma troca de contexto?", e ao ler ficou claro que esse FPGA tem vários (e maiores) LUTs, o suficiente para não se reprogramar por inteiro, apenas por blocos/pedaços. Assim ele lê o bitfile, programa um pedaço suficiente para executar o conjunto de instruções A e executa-o, enquanto isso ele lê outro bitfile e vê que o tipo de instrução (e unidades de execução) são diferentes, logo enquanto executa o conjunto A em um bloco ele programa outro bloco para o conjunto B e quando o switch acontecer, as unidades de execução estão prontas. Se o conjunto A não for mais utilizado ele "limpa" aquele bloco para não puxar recursos do sistema e assim repete-se esse esquema, indefinidamente.
Curioso é que esses blocos não só mudam completamente a forma de executar conforme o bitfile, ele também pode expandir ou diminuir de acordo com o que está sendo executado no bitfile: Digamos que o bloco A está fazendo cálculos na proporção de 20% INT e 80% FP, e ai as instruções mudam para uma proporção de 80% INT e 20% FP. Este FPGA analisa com antecedência o bitfile inteiro para detectar isso e prepara dinamicamente outro bloco para aumentar a quantidade de unidades de inteiro, assim quando a proporção mudar já se terá unidades suficientes para não haver gargalo ou redução de desempenho (e logo após o FPGA irá reduzir a quantidade de unidades FP). Isso é muuuuito legal, também é dito que esse método abordado na patente utiliza inteligência artificial para se reprogramar e "adivinhar" quando as unidades precisam ser expandidas e encolhidas, além de oferecer ao programador na hora da sintetização do bitfile opções mais otimizadas de código, caso existam
Em spoiler segue uns trechos da patente que fala disso da redução do tempo de switch:

PS1: As possibilidades que essa patente mostra são muitas mesmo, e baixar mais RAM é até estranho de se pensar mas com esse sistema será possível mesmo xD
PS2: Perdoem este off-topic, me empolguei, mas não é tão off assim não =X
Rapaz, eu não iria muito pelo o que o WccfTech diz não, ele nem sequer entendeu a patente, veja o que escreveram lá: "[Este método abordado] permitiria que cada chip da GPU se comunicasse com a CPU diretamente, bem como com outros chips por meio do crosslink passivo. [...] Este design sugere que cada chip de GPU será uma GPU em seu próprio direito e totalmente endereçável pelo sistema operacional."No site Wcctech foi explanado também sobre o ganho de aproveitamento do wafer que esta patente traria na fabricação de GPUs:
AMD Files MCM Based GPU Patent - Finally Bringing The MCM Approach To Radeon GPUs?
AMD has filed a patent for something that everyone knew would eventually happen: an MCM GPU Chiplet design. Spotted by LaFriteDavid over at Twitter and published on Freepatents.com, the document shows how AMD plans to build a GPU chiplet graphics card that is eerily reminiscent of its MCM based...wccftech.com
E sobre o novo chip NAVI, será que a AMD estaria preparando versões das placas usando memória HBM para concorrer com as futuras RTX 3000 Super? Ou então uma nova variante de GPU mais potente que a atual?
Não preciso dizer que está completamente errado, não é? A patente deixa claro que apenas um chiplet se comunica com a CPU e apenas este chiplet seria endereçável pelo S.O. Quanto ao ganho de aproveitamento do waffer... isso é o óbvio, estamos encaminhando para MCM/Chiplet justamente por estar se tornando impraticável chips de 600mm² ou maiores, em todos os sentidos (produção, custo, consumo, temperatura, engenharia), mas o cálculo do WccfTech está completamente equivocado aqui xD
Ele fez o seguinte: Um waffer de 200mm² rende 45 chips monolíticos de 484mm² (22x22mm), enquanto que este mesmo waffer rende 202 chiplets de 121mm² (11x11mm). Então se partirmos esse monolítico em quatro chiplets teríamos 50 GPUs ao invés de 45, um ganho de 11%. Legal, mas essa divisão está errada, pois o chiplet deverá ter unidades extras para permitir a comunicação entre eles (IF PHY no caso dos Ryzens, HBX PHY no caso da patente) e isso tornaria seu die maior. Sei que foi um cálculo só para exemplificar, mas propagar erro é um problema e nessa área de hardware isso se torna um tipo de vírus =S
Bem, se fizermos o cálculo certo e envolvermos no meio a taxa de erro do waffer perceberemos que o rendimento para chiplets é sempre maior, e se o monolítico for grande o rendimento é insanamente maior (nesse exemplo de 484mm² não seriam apenas 11% de ganho, seria algo entre 30~45%). Quanto à esse novo chip da Navi, não tem como ele ter mais unidades computacionais, o chip já é grande o suficiente com 80, e como apenas a variante XTX tem um H, creio que virá algo para ir contra a 3090, apenas isso (além de que HBM para placas mais baratas não tornaria estas placas baratas). Quanto à quantidade de memória, vai uma explicação abaixo:
Como o InfinityCache eleva a largura efetiva para 1664GB/s, esta placa precisaria aproximadamente desta velocidade de forma real para entregar um 4K sem restrições na uArch, então precisaríamos de seis pilhas HBM2 a 1GHz para alcançarmos 1536GB/s (6stacks*1024bits*2000Mbps/8), com um total de 24GB ou 48GB de memória, ou seria utilizado quatro pilhas Flashbolt HBM2E a 1.6GHz para alcançarmos 1640GB/s, mas a quantidade de memória seria de 16GB ou 32GB. Essa segunda possibilidade sairia mais barata, e ainda abriria a possibilidade de se usar o HBM2E da SKHynx e assim alcançar 1843GB/s nessas mesmas quantidades de memória. Como a possível meta dela seria a 3090 e seus 1500 dólares, daria para vermos todas essas possibilidades de memória, então eu chutaria 24GB com 6 pilhas HBM2 (maior custo de fabricação, maior consumo, mais frio) ou 32GB com 4 pilhas FB-HBM2E (custo de fabricação levemente menor, menor consumo, mais quente).Será que virá com mais memória tbm? Além dos 16 GB da 6900 "normal"?
A versão com 10GB e 160bits da Navi22 será exclusiva para notebooks, até o presente momento nenhum leak indica que esta versão venha para desktop e se vir como RX 6700 o desempenho dela não será equivalente a uma RX 5700XT, será bem pior. É uma possibilidade, mas não creio nela não, fico com a ideia de que as 6700 serão iguais às 6800, ou seja, variação de desempenho e CUs num mesmo barramento e VRAM6700 não seria 10gb e 6700xt 12gb? Mesmo por 300$ vai ser um bom CxB...uma placa de 10/12gb por 300$ enquanto a 3060 6gb deve chegar por 300$ (ou mais até)
Última edição:
Impressões iniciais:
Desempenho inacreditável; absolutamente fantástico esse Projeto da AMD (RX 6800XT); além de um monstruoso desempenho bruto, sua arquitetura brilha e mostra o que há de melhor disponível ao consumidor.
O que falarei é baseado em um teste de 10 Jogos num prazo de 4/5 horas... (Ainda testarei RayTracing e adicionarei aqui minhas observações).
A placa simplesmente sobra em 4K. (60hz tá safe; acho que 75hz é onde começa a se exigir adaptações).
Média é 70/80fps no máximo na maior parte de jogos AAA atuais; um ou outro fica entre 60 e 70. Nessa configuração estou vendo consumo de Vram entre 10GB e 14GB. (Finalmente posso usar minha tela sem medo de ser feliz).
A placa gera mais de 100fps em jogos competitivos no Ultra também. Ou seja, é porque não existe monitores competitivos em 4K de forma popular ainda... mas para o pessoal do competitivo que gosta de 144hz e um jogo no Low, não precisa nem reduzir resolução; ela já faz isso em 4K tranquilo.
Essa placa fica muito subutilizada em qualquer resolução abaixo disso... pelo menos hoje; e é assustador ver tudo isso com um consumo menor que 300W.
O upgrade em relação a RX 5700XT foi absurdo... Claro que já era esperado, mas me espantou tanta superioridade não no desempenho, mas na arquitetura em si...
Os drivers estão excelentes, quase que perfeitos. Joguei 5 horas na mais perfeita harmonia realizando os testes e usando tecnologias como o Enhanced Sync, Anti Lag, RIS... (Faltou HDR e Freesync).
O problema de stutter por personalização da Fan que foi meu grande calcanhar de aquiles na RX 5700XT simplesmente não existe nessa VGA, e está melhor fazer OC pelo driver do que por outro lugar (Um adeus ao MPT finalmente).
Você percebe o capricho do Software com ela principalmente na parte de OC.
Já comecei a brincar com overclock já que sou um grande aficionado, e é claro que ainda precisarei de mais tempo para uma apuração precisa, mas já consegui algumas observações preliminares:
* com 1090mv (Menos é instável e já está confirmado) consigo algo entre 2500mhz e 2600mhz. (Efetivamente é 2550mhz ou mais em jogos).
* com 1100mv (Talvez consiga diminuir um pouco; não afinei) consigo algo entre 2550mhz e 2650mhz. (Efetivamente 2590/2615Mhz em jogos).
Os Clocks que citei podem aumentar em jogos mais leves dentro da zona de cada perfil.
Ainda não sei o limite máximo de overclock da placa dentro dos 1150mv. Isso foi o que consegui testar e as temperaturas desses perfis não variaram. (Falarei logo a frente sobre).
A temperatura foi algo que achei muito tranquilo; foi necessário 70% de Fan para manter a VGA em 70°C na Edge e 90/95°C na Tjuction em Full Load. (Semelhante a minha RX 5700XT Pulse, mas em um projeto referência).
Com 70%; não ouvi nada das Fans no meu Gabinete. (Elas são muito silenciosas mesmo em alta rotação; o que me surpreendeu).
Ponto Fraco: Achei o conteúdo da caixa muito simples; acompanha literalmente só a VGA e um manual de instrução conforme a foto.
Ponto Forte: A AMD está de parabéns nesse modelo referência, é de fato bem eficiente mesmo em overclock e você sente que a construção é caprichada (blackplate, toda no metal, três fans; e tem uma presença dá marca muito forte no seu acabamento que gostei bastante). Esse modelo não é nada comparado ao vexame da versão referência que foi utilizada na RX 5700XT que só faltava pegar "fogo" sem UV.
Meu R5 3600 Turbinado tá lidando até bem em 4K, mas se diminuir a resolução um pouquinho já vai faltar IPC para extrair o máximo. (Gargalo).
Em 4K, em um cenário ou outro teve uma leve queda para 90% de uso, ou seja, numa situação excepcional o R5 3600 gargala mesmo em 4K, e o meu tem um overclock bem forte... Aposto que já estou tendo uma perda de desempenho mesmo assim, só não é possível sentir tanto porque os Ryzen 3000 são bem decentes.
Em stock ou com overclock básico, posso afirmar com um índice muito alto de certeza que existe gargalo até em 4K. (Não subestimem processador com essa placa; ela coloca quase todos os atuais em "cheque" pelo que vejo).
Quem quiser o máximo da placa, precisa partir para um Ryzen 5000; não é urgente se você já tem um processador recente. (Prevejo Mínimas, Médias melhores em resolução alta como 1800/2160p - Abaixo disso é gargalo se não tiver um IPC desse nível que citei).
Farei um up numa oportunidade decente e com preços normalizados.
Uma coisa que ficou bem evidente pra mim é que a AMD simplesmente não quis deixar essa VGA ser mais forte do que é hoje; claramente a BIOS limita ela. E isso não é algo que senti na RX 5700XT.
Na RDNA 1 existia um limite do OC e ele era de fato o limite real e era bem explicito; em RDN2; estou fazendo overclock, mas parece que não estou nem perto de chegar no limite dela... Sinto que vou bater o teto de voltagem e o clock só não vai subir mais de forma estável por isso.
1150mv de voltagem? (RDNA1 já tinha limite em 1200mv).
15% de PWL? (RDNA1 tinha 50%).
OC em Vram consegui estável os 2150Mhz no FastTiming. (2140Mhz efetivo). Pra quem não sabe, é o máximo da VGA. Foi um clique e pronto; estável.
Fico pensando: Se a minha placa que é referência, OC não parece um limite... imagina em um modelo Custom onde a capacidade de manter temperaturas baixas podem ser melhor ainda...
RDNA2 é simplesmente um projeto brilhante. Fica nítido que RDNA 1 era o escopo do que estava por vim, e é engraçado pensar que a AMD tem RDNA3 planejado. (Se conseguirem um novo pulo, além da redução de litografia... enfim, quero só ver).
Essa placa só não foi totalmente melhor que a RTX 3080 porque a AMD não quis... Consumo baixo; ela poderia deixar consumir um pouco mais e ter mais desempenho... Possui um potencial de overclock que nitidamente é limitado pela BIOS... Poderiam ter explorado isso melhor.
Senti que vamos começar a ver o brilho daquilo que Zen foi e é a partir de agora em VGAs também... Nvidia que se cuide e dê um jeito de se livrar da Samsung logo. Na próxima geração vai levar fumo se não fazer algo a respeito... (E falo isso de forma bem imparcial mesmo).
Agora sério.... RX 5700XT consome 200/230W +/-.
Essa placa consome 250/290W pelo que vi aqui já em overclock... é um ganho por eficiência simplesmente absurdo.
O desempenho mudou colossalmente... o consumo quase que nada.
Enfim, irei curtir a placa, depois trago mais resultados de OC.
Nota: 9,0.
Obs: Não pode levar um 10 porque fica abaixo do concorrente em RayTracing, ainda é ausente uma alternativa ao DLSS, e o preço ainda é muito alto, fora os motivos citados; o fato de que o potencial de Overclock está claramente limitado pela BIOS.
*Só não vou blocar pra não perder a garantia, mas um BIOSmod nessa VGA seria incrível de ver.

@Snap aí o post que tu perguntou no tópico das verdinhas
Por qual motivo voce acha que a 6700 normal vai ser pior que a 5700 xt?Rapaz, ao meu ver essa compra da Xilinx vai render muito melhor que a da Altera pela Intel, o InfinityFabric como intercomunicação de baixa latência e alta velocidade será uma combinação bem promissora para criar um XPU eficiente.
Sim, falaram que o PCIe tem latência alta e não deram alternativa, então o que veio na cabeça foram duas possibilidades, uma comunicação diferente (como o NVLink ou CXL) ou esse FPGA em um interposer MCM como coprocessador se comunicando por InfinityFabric (ou o recém mostrado HBX), são as únicas possibilidades que uniriam velocidade acima e latência abaixo do que o PCI-express pode oferecer até sua 6ª geração.
Mas a pergunta que também estava na minha cabeça logo ao começar a ler a patente foi exatamente esta sua, "Como faria para reprogramar de forma tão rápida após uma troca de contexto?", e ao ler ficou claro que esse FPGA tem vários (e maiores) LUTs, o suficiente para não se reprogramar por inteiro, apenas por blocos/pedaços. Assim ele lê o bitfile, programa um pedaço suficiente para executar o conjunto de instruções A e executa-o, enquanto isso ele lê outro bitfile e vê que o tipo de instrução (e unidades de execução) são diferentes, logo enquanto executa o conjunto A em um bloco ele programa outro bloco para o conjunto B e quando o switch acontecer, as unidades de execução estão prontas. Se o conjunto A não for mais utilizado ele "limpa" aquele bloco para não puxar recursos do sistema e assim repete-se esse esquema, indefinidamente.
Curioso é que esses blocos não só mudam completamente a forma de executar conforme o bitfile, ele também pode expandir ou diminuir de acordo com o que está sendo executado no bitfile: Digamos que o bloco A está fazendo cálculos na proporção de 20% INT e 80% FP, e ai as instruções mudam para uma proporção de 80% INT e 20% FP. Este FPGA analisa com antecedência o bitfile inteiro para detectar isso e prepara dinamicamente outro bloco para aumentar a quantidade de unidades de inteiro, assim quando a proporção mudar já se terá unidades suficientes para não haver gargalo ou redução de desempenho (e logo após o FPGA irá reduzir a quantidade de unidades FP). Isso é muuuuito legal, também é dito que esse método abordado na patente utiliza inteligência artificial para se reprogramar e "adivinhar" quando as unidades precisam ser expandidas e encolhidas, além de oferecer ao programador na hora da sintetização do bitfile opções mais otimizadas de código, caso existam
Em spoiler segue uns trechos da patente que fala disso da redução do tempo de switch:
PS1: As possibilidades que essa patente mostra são muitas mesmo, e baixar mais RAM é até estranho de se pensar mas com esse sistema será possível mesmo xD
PS2: Perdoem este off-topic, me empolguei, mas não é tão off assim não =X
Rapaz, eu não iria muito pelo o que o WccfTech diz não, ele nem sequer entendeu a patente, veja o que escreveram lá: "[Este método abordado] permitiria que cada chip da GPU se comunicasse com a CPU diretamente, bem como com outros chips por meio do crosslink passivo. [...] Este design sugere que cada chip de GPU será uma GPU em seu próprio direito e totalmente endereçável pelo sistema operacional."
Não preciso dizer que está completamente errado, não é? A patente deixa claro que apenas um chiplet se comunica com a CPU e apenas este chiplet seria endereçável pelo S.O. Quanto ao ganho de aproveitamento do waffer... isso é o óbvio, estamos encaminhando para MCM/Chiplet justamente por estar se tornando impraticável chips de 600mm² ou maiores, em todos os sentidos (produção, custo, consumo, temperatura, engenharia), mas o cálculo do WccfTech está completamente equivocado aqui xD
Ele fez o seguinte: Um waffer de 200mm² rende 45 chips monolíticos de 484mm² (22x22mm), enquanto que este mesmo waffer rende 202 chiplets de 121mm² (11x11mm). Então se partirmos esse monolítico em quatro chiplets teríamos 50 GPUs ao invés de 45, um ganho de 11%. Legal, mas essa divisão está errada, pois o chiplet deverá ter unidades extras para permitir a comunicação entre eles (IF PHY no caso dos Ryzens, HBX PHY no caso da patente) e isso tornaria seu die maior. Sei que foi um cálculo só para exemplificar, mas propagar erro é um problema e nessa área de hardware isso se torna um tipo de vírus =S
Bem, se fizermos o cálculo certo e envolvermos no meio a taxa de erro do waffer perceberemos que o rendimento para chiplets é sempre maior, e se o monolítico for grande o rendimento é insanamente maior (nesse exemplo de 484mm² não seriam apenas 11% de ganho, seria algo entre 30~45%). Quanto à esse novo chip da Navi, não tem como ele ter mais unidades computacionais, o chip já é grande o suficiente com 80, e como apenas a variante XTX tem um H, creio que virá algo para ir contra a 3090, apenas isso (além de que HBM para placas mais baratas não tornaria estas placas baratas). Quanto à quantidade de memória, vai uma explicação abaixo:
Como o InfinityCache eleva a largura efetiva para 1664GB/s, esta placa precisaria aproximadamente desta velocidade de forma real para entregar um 4K sem restrições na uArch, então precisaríamos de seis pilhas HBM2 a 1GHz para alcançarmos 1536GB/s (6stacks*1024bits*2000Mbps/8), com um total de 24GB ou 48GB de memória, ou seria utilizado quatro pilhas Flashbolt HBM2E a 1.6GHz para alcançarmos 1640GB/s, mas a quantidade de memória seria de 16GB ou 32GB. Essa segunda possibilidade sairia mais barata, e ainda abriria a possibilidade de se usar o HBM2E da SKHynx e assim alcançar 1843GB/s nessas mesmas quantidades de memória. Como a possível meta dela seria a 3090 e seus 1500 dólares, daria para vermos todas essas possibilidades de memória, então eu chutaria 24GB com 6 pilhas HBM2 (maior custo de fabricação, maior consumo, mais frio) ou 32GB com 4 pilhas FB-HBM2E (custo de fabricação levemente menor, menor consumo, mais quente).
A versão com 10GB e 160bits da Navi22 será exclusiva para notebooks, até o presente momento nenhum leak indica que esta versão venha para desktop e se vir como RX 6700 o desempenho dela não será equivalente a uma RX 5700XT, será bem pior. É uma possibilidade, mas não creio nela não, fico com a ideia de que as 6700 serão iguais às 6800, ou seja, variação de desempenho e CUs num mesmo barramento e VRAM
(Estou pensando em comprar a 6700 xt ou a 3060 ti)
A RX6700 normal só será pior que a 5700XT caso ela tenha 10GB de memória, caso ela tenha 12GB ela será igualPor qual motivo voce acha que a 6700 normal vai ser pior que a 5700 xt?
(Estou pensando em comprar a 6700 xt ou a 3060 ti)
PS: Essa equivalência não sou eu que estou dando, é o desempenho vazado mês passado, onde a 6700XT seria 20~25% melhor que a 5700XT e a 6700 comum seria equivalente à 5700XT, mas essa informação leva em consideração uma 6700 comum em um barramento de 192bits. Caso seja 180bits ela terá ~7% menos largura de banda real e isso a fará ser quase 10% inferior à 5700XT (no caso, ~7% superior à 5700 comum).
---
Só para reforçar o detalhe lá da patente, esse esquema de chiplet dela é uma tomada diferente da usada nos Ryzens. Esse artigo aqui do Semiengineering fala sobre as tomadas diferentes de MCM, vale a leitura para quem se interessar.
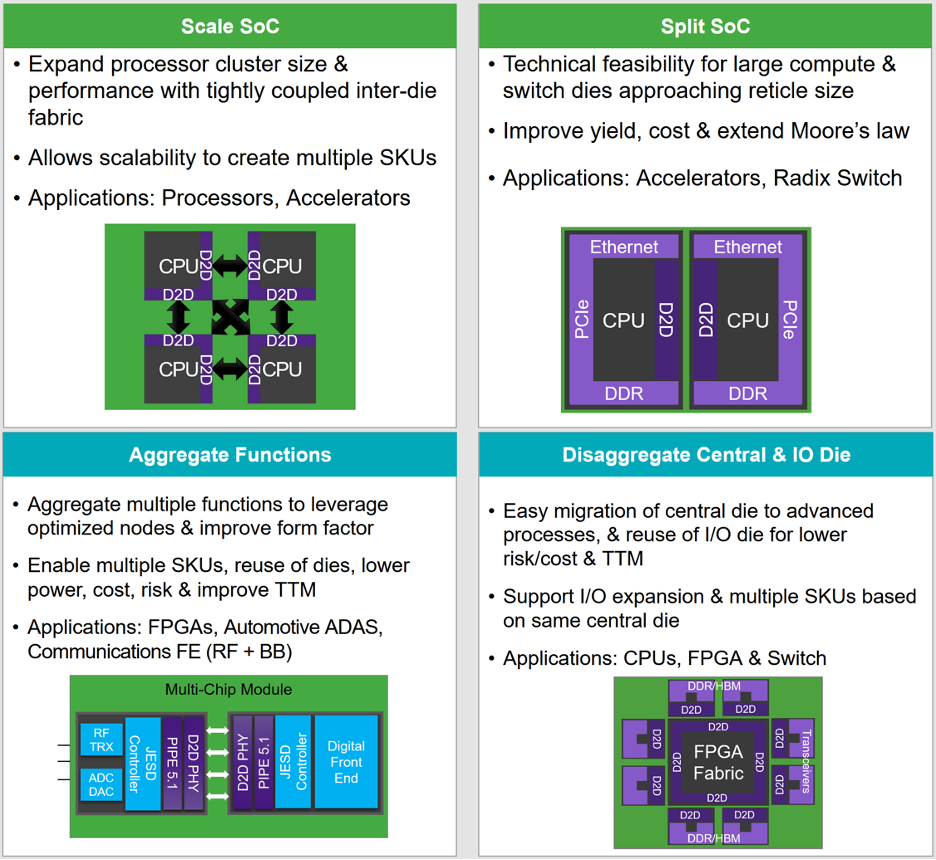
Designs Beyond The Reticle Limit
Chips are hitting technical and economic obstacles, but that is barely slowing the rate of advancement in design size and complexity.
Essa imagem aqui é o que mais importa, para quem não quer ler: Os quatro modos de se fazer MCM

Pessoal, to pensando em vender a minha 2060 super pra pegar uma 6800xt. Acham que vale a pena?
Quanto voces acham que da pra pegar numa 2060 super usada?
Quanto voces acham que da pra pegar numa 2060 super usada?
Talvez seja padrão da serie mid que pode vir dia 12 essa refrigeração fria das founders .Após duas semanas com minha rx 6800 xt, só amores pela placa, jogo warzone no quase tudo no full e fps médio de 180. A temperatura média dela tá ficando por volta dos 55 graus, com temperatura ambiente em 27 graus
Eu ainda não consigo compreender como recebi com antecedência...Até hoje nada da brasspress entregar, quase 20 dias com a encomenda kkkkk

Foi sorte, foi... Mas inacreditável.
As vezes fico na dúvida, mas acho que o tópico é das RX 5xxx né? 
De qualquer forma, devido ao preço ainda mais absurdo das RTX 2060, deverei pegar uma RX 5600XT. Alguém sabe se a série tá funcionando bem, em outras palavras, se não estão saindo drivers malucos? Confesso que ainda tenho um certo receio da AMD em relação a isso. Eu nem vou jogar muita coisa, fora que minha jogatina vai ser bem limitada. Até por isso não quero gastar muito em VGA e nem sei se trocarei esse lixo de processador por enquanto.
Tava pensando em pegar uma RTX 2060 pra suprir minhas jogatinas cada vez mais raras e desisti ao ver os preços. Estão pedindo R$ 2500 na 2060 nova, então talvez vc encontre loucos dispostos a pagar nessa faixa entre R$ 2500-2800 numa RTX 2060 Super usada.
De minha parte, se quiser R$ 2 mil nela eu compro rs.
De qualquer forma, devido ao preço ainda mais absurdo das RTX 2060, deverei pegar uma RX 5600XT. Alguém sabe se a série tá funcionando bem, em outras palavras, se não estão saindo drivers malucos? Confesso que ainda tenho um certo receio da AMD em relação a isso. Eu nem vou jogar muita coisa, fora que minha jogatina vai ser bem limitada. Até por isso não quero gastar muito em VGA e nem sei se trocarei esse lixo de processador por enquanto.
Pessoal, to pensando em vender a minha 2060 super pra pegar uma 6800xt. Acham que vale a pena?
Quanto voces acham que da pra pegar numa 2060 super usada?
Tava pensando em pegar uma RTX 2060 pra suprir minhas jogatinas cada vez mais raras e desisti ao ver os preços. Estão pedindo R$ 2500 na 2060 nova, então talvez vc encontre loucos dispostos a pagar nessa faixa entre R$ 2500-2800 numa RTX 2060 Super usada.
De minha parte, se quiser R$ 2 mil nela eu compro rs.
Users who are viewing this thread
Total: 3 (membros: 0, visitantes: 3)