www.anandtech.com
A equipe AMD nos surpreendeu aqui. O que parecia uma palestra muito par-para-o-curso da Computex se transformou em uma demonstração incrível do que a AMD está testando no laboratório com as novas tecnologias de tecido 3D da TSMC. Já cobrimos o 3D Fabric antes, mas a AMD está fazendo um bom uso ao empilhar seus processadores com cache adicional, permitindo largura de banda super rápida e melhor desempenho em jogos. Essa é a afirmação de qualquer maneira, e a AMD apresentou seu novo processador de demonstração no palco na Computex. Aqui está uma descrição mais detalhada do que ele realmente é.
Chiplets 3D: a próxima etapa
A AMD anunciou que estava estudando tecnologias de empilhamento 3D com 'X3D'
em março de 2020 em seu Dia do Analista Financeiro, com um diagrama muito estranho mostrando um processador chip com o que parecia ser pilhas de HBM ou algum tipo de memória externa. Na época, a AMD disse que era uma mistura de tecnologias de empacotamento 2.5D e 3D, permitindo uma densidade de largura de banda de 10x ou mais. O 'X' em 'X3D' foi feito para representar Hybrid, e a tecnologia foi criada para 'o futuro'. Desde então, a TSMC anunciou sua linha de tecnologias 3D Fabric, um nome amplo para sua combinação de ofertas de integração 2.5D e 3D.
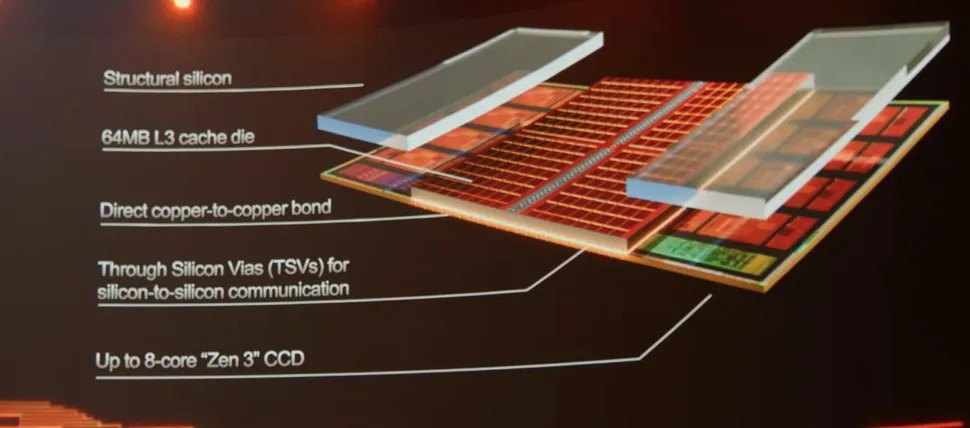
Hoje a AMD apresentou o primeiro estágio de sua jornada com chips 3D. O primeiro aplicativo é um cache empilhado em cima de um chip de processador padrão. No palco, Lisa Su apresentou um dos processadores AMD Ryzen 5000 dual-chip com núcleos Zen 3. Em um dos chips de computação, uma SRAM de 64 MB construída em 7nm do TSMC foi integrada na parte superior, efetivamente triplicando a quantidade de cache a que os núcleos têm acesso.
Isso significa que o chip Ryzen 5000 original, com oito núcleos tendo acesso a 32 MB de cache L3, agora se torna um complexo de oito núcleos com acesso a 96 MB de cache L3. As duas matrizes são ligadas com Through Silicon Vias (TSVs), passando energia e dados entre as duas. A AMD afirma que a largura de banda total do cache L3 aumenta para além de 2 TB / s, o que seria tecnicamente mais rápido do que o cache L1 no chip (mas com latência mais alta).
Como parte do diagrama do chip, os TSVs seriam ligações diretas de cobre a cobre. O die do cache não é do mesmo tamanho que o complexo do núcleo e, como resultado, silício estrutural adicional é necessário para garantir que haja pressão igual em ambas as matrizes de computação inferior e superior. Ambas as matrizes são desbastadas, com o objetivo de habilitar o novo chip no mesmo substrato e tecnologia de dissipador de calor atualmente em uso nos processadores Ryzen 5000.
O protótipo do processador mostrado no palco tinha um de seus chips usando essa nova tecnologia de cache. O outro chip foi deixado como padrão para mostrar a diferença, e o chip que tinha o dado cache "exposto" tornou-o óbvio e comparável ao chip normal não integrado. A CEO Dra. Lisa Su disse que a SRAM de 64 MB neste caso é um design de 6 mm x 6 mm (36 mm2), o que a coloca em pouco menos da metade da área do molde de um chip Zen 3 completo.
Em um produto completo, Lisa explicou que todos os chipsets teriam o cache empilhado habilitado, para 96 MB de cache por chip, ou 192 MB no total para um processador como esse que tem 12 ou 16 núcleos.
Como parte da tecnologia, foi explicado que esta embalagem permite uma densidade de interconexão> 200x em comparação com a embalagem 2D normal (algo que já conhecemos do empilhamento HBM), um aumento de densidade> 15x em comparação com a tecnologia de microbump (um tiro direto através do arco dos Foveros da Intel) e eficiência de interconexão 3x melhor em comparação com microbumps. A interface TSV é uma interconexão direta de cobre molde a molde, o que significa que a AMD está usando a tecnologia Chip-on-Wafer da TSMC. O Dr. Su afirmou no palco que esses recursos tornam esta tecnologia de empilhamento de chips "ativo-sobre-ativo" mais avançada e flexível do setor.
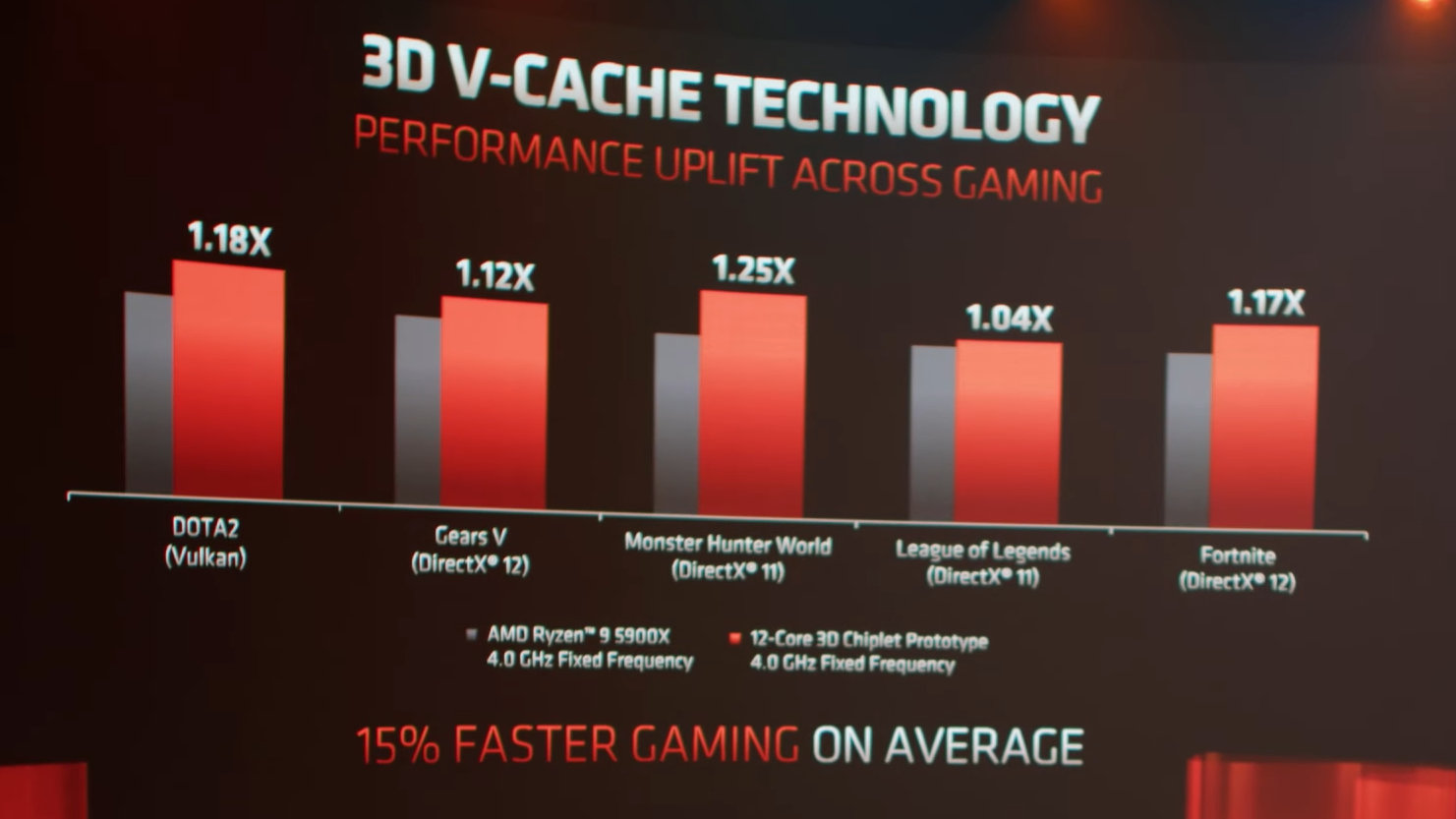
Quanto às demonstrações de desempenho, a AMD comparou um antes e depois de usar o Gears of War 5. De um lado estava um processador Ryzen 9 5900X de 12 núcleos padrão, enquanto o outro era um protótipo usando o novo V-Cache 3D construído sobre um Ryzen 9 5900X . Ambos os processadores foram fixados em 4 GHz e emparelhados com uma placa de vídeo sem nome.
Nesse cenário, o ponto de comparação é que um processador tem 64 MB de cache L3, enquanto o outro tem 192 MB de cache L3. Um dos pontos de venda dos processadores Ryzen 5000 era o cache L3 estendido disponível para cada processador para ajudar no desempenho dos jogos, e mover isso para 96 MB por chip estende essa vantagem ainda mais, com a AMD mostrando um ganho de FPS de + 12% (184 FPS vs 206 FPS) com o tamanho de cache aumentado em 1080p. Em uma série de jogos, a AMD afirmou + 15% de desempenho médio em jogos:
- DOTA2 (Vulkan): + 18%
- Gears 5 (DX12): + 12%
- Monster Hunter World (DX11): + 25%
- League of Legends (DX11): + 4%
- Fortnite (DX12): + 17%
Esta não é uma lista exaustiva de forma alguma, mas é uma leitura interessante. A afirmação da AMD aqui é que um aumento de + 15% é semelhante a um salto de geração de arquitetura completa, permitindo efetivamente uma rara melhoria por meio de diferenças filosóficas de design. Aqui na AnandTech , gostaríamos de observar que, à medida que se torna mais difícil detalhar os novos nós de processo, os aprimoramentos filosóficos do projeto podem se tornar o principal impulsionador do desempenho futuro.
A AMD diz que fez grandes avanços com a tecnologia e está pronta para colocá-la em produção com seus processadores de última geração até o final do ano. Não foi declarado sobre quais produtos ele viria, se era para consumidor ou empresa. A propósito disso, a AMD disse que o Zen 4 está previsto para ser lançado em 2022.
A Análise AnandTech
Bem, isso foi inesperado. Sabíamos que a AMD iria investir na tecnologia 3D Fabric da TSMC, mas acho que não esperávamos que fosse assim em breve ou com uma demonstração em um processador de desktop primeiro.

Começando com a tecnologia, este é claramente o SoIC Chip-on-Wafer da TSMC em ação, embora com apenas duas camadas. A TSMC demonstrou doze camadas, no entanto, essas eram camadas não ativas. O problema com o empilhamento de silício está na atividade e, posteriormente, nas térmicas. Temos visto com outro hardware TSV empilhados, como HBM, que SRAM / memória / cache é o veículo perfeito para isso, pois não acrescenta
que tanto com as exigências térmicas do processador. A desvantagem é que o cache que você empilhar é pouco mais do que apenas cache.
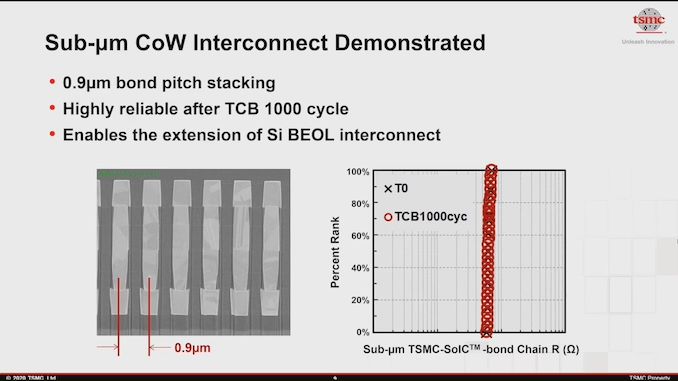
Passando para o chip em si, foi alegado que o chip de cache L3 de 64 MB tem 6 mm x 6 mm, ou 36 mm2, e é construído em TSMC 7 nm. O fato de ser construído em TSMC 7nm será um ponto crítico aqui - você pode pensar que um chip de cache pode ser mais adequado para um nó de processo mais barato. A compensação no custo é a potência e a área do die (não vale a pena considerar o rendimento em um dado tão pequeno). Se a AMD quiser fazer esses chips de cache em TSMC 7nm, isso significa que um Zen 3 com cache adicional requer 80,7 mm2 para o chip Zen 3 como normal, depois outros 36 mm2 para o cache, exigindo efetivamente 45% mais silício por processador. Embora atualmente haja uma escassez de silício, isso pode afetar a quantidade de processadores disponibilizados para uso mais amplo. Pode ser por isso que a AMD disse que estava olhando primeiro para os produtos de 'ponta'.
Agora, adicionar 64 MB de cache a um chip que já tem 32 MB de cache L3 não é tão simples quanto parece. Se a AMD o estiver integrando diretamente como uma adjacência ao cache L3, então temos um cache L3 de camada dupla. É provável que o acesso a esses 64 MB exija mais energia, mas isso fornece uma largura de banda maior. Dependeria da carga de trabalho se os 32 MB normais fossem suficientes, em comparação com os 64 MB extras fornecidos pelo dado empilhado. Podemos ver os 64 MB extras vistos como um cache L4 equivalente, no entanto, o problema aqui é que, para que os 64 MB extras vão para a memória principal, ele tem que passar pelo chip principal abaixo dele. Esse é um consumo de energia adicional que vale a pena observar. Estou muito interessado em ver como o perfil de memória da perspectiva de um núcleo sai com esse chip extra, e como a AMD está integrando isso à estrutura. A AMD afirmou que é um design baseado em SRAM, então infelizmente não é nada sofisticado como memória persistente, o que teria sido um ethos de design totalmente diferente. Ao aderir à SRAM, significa que pelo menos ela pode fornecer melhorias de desempenho de forma contínua.
No desempenho, vimos a profundidade do cache L3 melhorar o desempenho dos jogos, tanto para jogos discretos quanto integrados. No entanto, o aumento da profundidade do cache L3 não faz muito mais pelo desempenho. Isso foi melhor exemplificado em nossa análise dos processadores Broadwell da Intel, com 128 MB de cache L4 (~ 77 mm2 na Intel 22nm), em que o cache extra apenas melhorou os jogos e os testes de compressão / descompressão. Será interessante ver como a AMD comercializa a tecnologia além dos jogos.
Finalmente, interceptação no mainstream - a AMD diz que está pronta para começar a integrar a tecnologia em seu portfólio de alta tecnologia com produção no final do ano. A AMD disse que o lançamento do Zen 4 em 5 nm será em 2022. Com base em escalas de tempo anteriores, previmos que a próxima família de processadores da AMD será em aproximadamente um lançamento em fevereiro de 2022. Se isso seria o Zen 4, não está claro neste ponto, mas também o Zen 4 está em 5nm e a AMD está apresentando este V-Cache 3D em 7nm. Não está claro se a AMD tem planos de monetizar esse recurso em 7nm ou se pode combinar um chip zen 4 de 5 nm com um chip de cache de 64 MB de 7 nm. Não seria muito difícil combinar os dois, no entanto, suspeito que a AMD pode querer empurrar sua tecnologia de cache em mais produtos premium do que o desktop Ryzen. Podemos ver edições únicas especiais à medida que a tecnologia avança na pilha.
Para concluir, tenho uma série de perguntas que gostaria de fazer à AMD. Espero obter algumas respostas e, se o fizer, voltarei com os detalhes.