No Warzone não.Tava pensando em pegar o 5600x mas vou acabar encarando o 3700x. Assim no troco de placa mãe por enquanto, ai quando sair a nova geração já troco tudo de uma vez.
Pra empurrar uma 3070 em quadHD (165hz pra competitivo/60 pra tripleAAA) o 3700x se vira bem, né?
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
[TÓPICO DEDICADO] AMD Ryzen Socket AM4 - Zen, Zen+, Zen 2 & Zen 3
- Iniciador de Tópicos DemonbrsX
- Data de Início
olha pra qualquer placa de vídeo acima da 3060 eu passaria longe da série 3000 do ryzen, um amigo meu tem um 3700x com uma rtx 3070 e em jogos competitivos é ridículo o quanto ele fica capado quando ultrapassa os 200 fps, ele joga fortnite, cs go e até pes, em todos ele faz muito menos fps do que deveria, a 3070 dele acaba rendendo uns 20 a 30% pior tipo no desempenho de uma rtx 2070 com um 5600xTava pensando em pegar o 5600x mas vou acabar encarando o 3700x. Assim no troco de placa mãe por enquanto, ai quando sair a nova geração já troco tudo de uma vez.
Pra empurrar uma 3070 em quadHD (165hz pra competitivo/60 pra tripleAAA) o 3700x se vira bem, né?
Complicado é achar uma placa mãe com recursos legais e um preço camarada kkkk Tenho uma Crosshair VI hero e ta dificil achar um modelo parecido.... vi a B550-E da asus, mas agora ela nao aparece mais em estoque e quando aparece é 2k+.Se vc quer jogar acima de 120fps em tudo é ideal vc pegar o 5600x.
To com receio de investir em mobo agora tb e a próxima geração ter que trocar tudo.
Outro fato, não ligo de ficar limitado nos 165hz, mas faço live também. Tinha receio do 5600x ficar um pouco pra trás no uso de games/lives. É bobeira minha? Ele leva na boa?
Pô cara, depende do que você ta buscando... Minha b450m steel legend de 650 reais me atende 100% com o 3700x...Complicado é achar uma placa mãe com recursos legais e um preço camarada kkkk Tenho uma Crosshair VI hero e ta dificil achar um modelo parecido.... vi a B550-E da asus, mas agora ela nao aparece mais em estoque e quando aparece é 2k+.
To com receio de investir em mobo agora tb e a próxima geração ter que trocar tudo.
Outro fato, não ligo de ficar limitado nos 165hz, mas faço live também. Tinha receio do 5600x ficar um pouco pra trás no uso de games/lives. É bobeira minha? Ele leva na boa?
Tem um user aqui do fórum que usa a b450m steel legend no 5800x dele numa boa também.
Placa mãe é o que menos faz diferença na performance do pc.
Isso pra fullHD né. QuadHD a diferença não é muito pq carrega mais a GPU e 4k a diferença nem existe praticamente.olha pra qualquer placa de vídeo acima da 3060 eu passaria longe da série 3000 do ryzen, um amigo meu tem um 3700x com uma rtx 3070 e em jogos competitivos é ridículo o quanto ele fica capado quando ultrapassa os 200 fps, ele joga fortnite, cs go e até pes, em todos ele faz muito menos fps do que deveria, a 3070 dele acaba rendendo uns 20 a 30% pior tipo no desempenho de uma rtx 2070 com um 5600x
Mas como a diferença de preço não é muito hoje em dia é bem melhor um 5600X do que um 3700X pra jogo mesmo.
Quando a moda RGB veio, qualquer coisa com essas 3 letras no produto, fazia custar mais que o dobro do que sem RGB.Quero só ver quanto vão cobrar aqui no Brasil essas novas APUs , dólar caiu.
Agora a moda mudou para VGA/GPU.
Vendedor lê que o produto tem isso, Ahhhhhh...mete a faca e torce, que os caras pagam.
ah sim de fato é pra full hd, mas imagino que pra jogos competitivos a resolução full hd ainda prevaleça, até pq pra esse foco aí de 200fps ou mais é só assim praticamenteIsso pra fullHD né. QuadHD a diferença não é muito pq carrega mais a GPU e 4k a diferença nem existe praticamente.
Mas como a diferença de preço não é muito hoje em dia é bem melhor um 5600X do que um 3700X pra jogo mesmo.
Boa tarde, tenho um ryzen 7 3700x vai fazer uns 2 anos... de vez em quando o pc reinicia sozinho, trava e reinicia. Não da tela azul apenas reinicia, porém acontece 90% das vezes sem ta jogando, apenas vendo filme ou navegando. ( as vezes passam dias sem acontecer e as vezes acontece varias vezes em um dia. )
Gostaria de saber se tem algum teste para saber se o problema é no processador. Ele não se encontra em over, temperaturas aparentemente normais, rodando o teste de estresse do fica em 81~83 graus.
Não é a placa de vídeo pois troquei recentemente de placa de vídeo e acontece mesma coisa.
Obrigado.
Gostaria de saber se tem algum teste para saber se o problema é no processador. Ele não se encontra em over, temperaturas aparentemente normais, rodando o teste de estresse do fica em 81~83 graus.
Não é a placa de vídeo pois troquei recentemente de placa de vídeo e acontece mesma coisa.
Obrigado.
AMD triplica cache de CPU Zen 3 usando tecnologia de empilhamento 3D

AMD triples Zen 3 CPU cache using 3D stacking technology
Not a pipe dream—CEO Lisa Su demonstrated a working 3D-stacked 5900X prototype.
AMD triplica cache de CPU Zen 3 usando tecnologia de empilhamento 3D
AMD triples Zen 3 CPU cache using 3D stacking technology
Not a pipe dream—CEO Lisa Su demonstrated a working 3D-stacked 5900X prototype.arstechnica.com
É tou vendo que vou esperar para trocar meu 3700x, essa nova tecnologia nos ryzen 5000 promete ..

Deve vir fim do ano. Mas o "brecinho"...É tou vendo que vou esperar para trocar meu 3700x, essa nova tecnologia nos ryzen 5000 promete ..
Boa tarde, tenho um ryzen 7 3700x vai fazer uns 2 anos... de vez em quando o pc reinicia sozinho, trava e reinicia. Não da tela azul apenas reinicia, porém acontece 90% das vezes sem ta jogando, apenas vendo filme ou navegando. ( as vezes passam dias sem acontecer e as vezes acontece varias vezes em um dia. )
Gostaria de saber se tem algum teste para saber se o problema é no processador. Ele não se encontra em over, temperaturas aparentemente normais, rodando o teste de estresse do fica em 81~83 graus.
Não é a placa de vídeo pois troquei recentemente de placa de vídeo e acontece mesma coisa.
Obrigado.
Sua placa mãe é uma Steel Legend b450?
Tem acontecido algo semelhante aqui com o meu 2700 non-x, mas o detalhe é que aqui dá tela azul, sem estar jogando e principalmente, com temperaturas estáveis (uso WC a cpu em idle/load para atividades leves não passa de 45°c)
APU AMD Ryzen 6000 “Rembrandt (Yellow Carp)” não contará com o Infinity Cache
AMD Rembrandt não obterá Infinity Cache
A AMD atualizou recentemente o kernel do Linux com informações sobre o próximo Yellow Carp APU.
AMD Ryzen 6000 "Rembrandt (Yellow Carp)" APU will reportedly not feature Infinity Cache - VideoCardz.com
AMD Rembrandt will not get Infinity Cache AMD has recently updated the Linux kernel with information on the upcoming Yellow Carp APU. Yellow Carp is a codename for the upcoming Rembrandt APU for next-gen laptops and next-gen desktop APUs. This is allegedly a successor to Cezanne that would...
 videocardz.com
videocardz.com
Yellow Carp é o codinome do próximo Rembrandt APU para laptops e APUs de desktop de última geração. Este é supostamente um sucessor de Cézanne que apresentaria a misteriosa arquitetura central Zen3 +, até agora a única parte que apareceu em um roteiro com um 'mais'.
Rembrandt também está trazendo uma grande mudança na arquitetura de GPU, será o primeiro APU baseado em Navi2 (RDNA2), seguindo Van Gogh, que ainda não foi lançado. Para a série móvel, Rembrandt será dividido como Cezanne nas séries H (alto desempenho) e U (baixa potência), o roteiro divulgado confirmou:
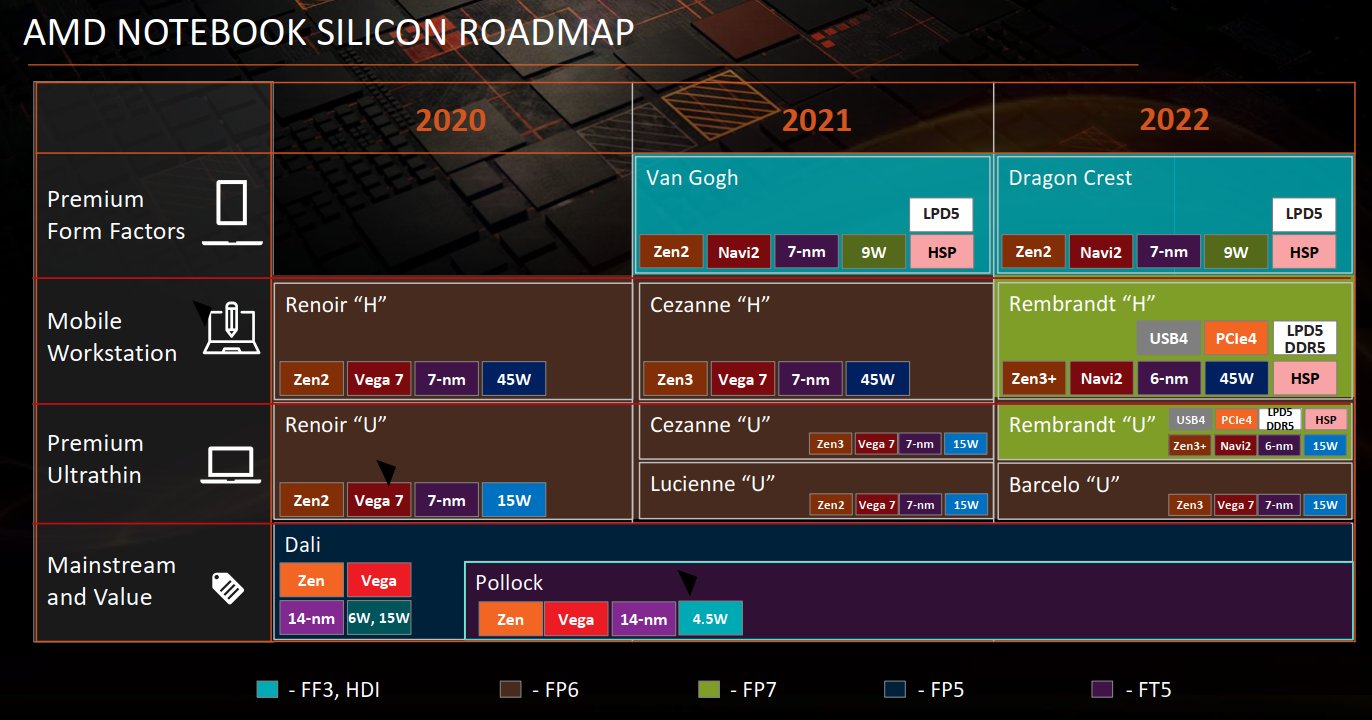
AMD Notebook Roadmap, Fonte: @ Broly_X1
O APU exigirá um novo soquete FP7, o que forçará os fabricantes de laptop a adotar os designs existentes para as novas placas-mãe e, possivelmente, as características de energia e térmicas da série de APU “Yellow Carp”. Isso é compreensível, já que Rembrandt traz grandes mudanças não apenas para o núcleo da CPU e GPU, mas também I / O. Rembrandt será a primeira APU da AMD a oferecer suporte aos padrões de memória DDR5 e LPDDR5. Também habilitará o suporte a PCIe Gen4, algo que Cezanne atualmente não oferece.
De acordo com algumas informações novas, Rembrandt iGPU não terá cache de nível 3 (L3), pelo menos não existe tal entrada na atualização recente do kernel do Linux (apenas cache L1 e L2).
Além disso, em vez de 8 unidades de computação por ShaderArray, Rembrandt terá 6. No entanto, o código não confirma o número total de UCs no APU. Os processos de fabricação do Zen3 + e 6nm também não foram confirmados, mas eles têm se repetido em rumores há um bom tempo, então seria surpreendente se eles fossem falsos.

Boas novidades para o AMD ZEN, relacionado a TSMC de forma indireta
7nm
6nm
5nm
4nm
3nm
Capacidade de 5 nm da TSMC para quadruplicar até 2023, a partir de 2020
ZEN 4 e RDNA 3 serão produzidos em 5nm, portanto é esperado que a AMD não tenha problemas de produção desses chip's
"TSMC diz que a construção da fábrica de chips do Arizona começou
/cloudfront-us-east-2.images.arcpublishing.com/reuters/POU6J4VDN5PQNKFJ5BERQ3ECHY.jpg)
 www.reuters.com
www.reuters.com
Atualização de fabricação da TSMC: N6 para combinar com a saída N7 por EOY, N5 rampa mais rápido, melhores rendimentos do que N7
Alguns destaques:
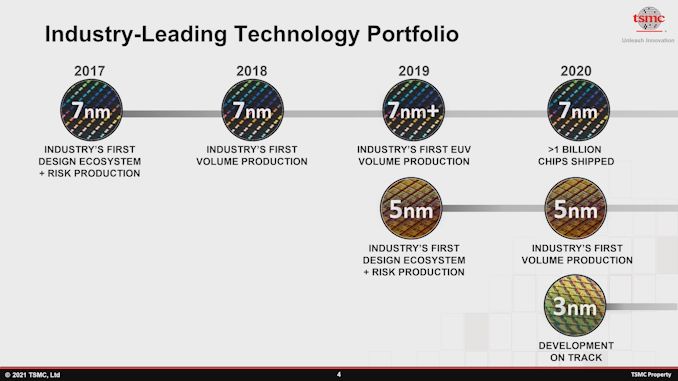
A TSMC separa seus nós de manufatura de ponta em três “famílias” de produtos: 7nm, 5nm e o próximo nó de manufatura de 3nm. Como muitos terão notado por meio de uma ampla gama de produtos ao longo dos últimos dois anos, a introdução do nó de 7 nm e a fabricação em massa da TSMC a partir de 2018 foi um verdadeiro tour de force para a fundição, conquistando uma liderança significativa na indústria em relação aos concorrentes mais próximos têm lutado para acompanhar até hoje.
Até o momento, a TSMC já despachou mais de 1 bilhão de chips de 7nm e a família de 7nm é considerada extremamente madura, com a fundição agora se concentrando em aumentar produtos de 5nm e próximos nós avançados de 3nm.
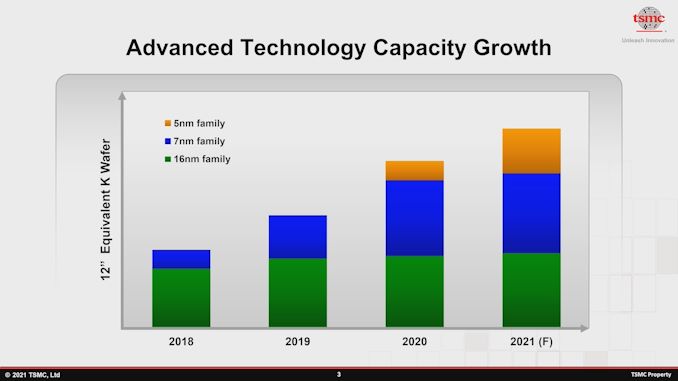
Em termos de capacidade da família de 7 nm, começando em 2021, a capacidade anual instalada está realmente começando a diminuir significativamente à medida que muitos clientes migram para os nós de processo mais avançados.
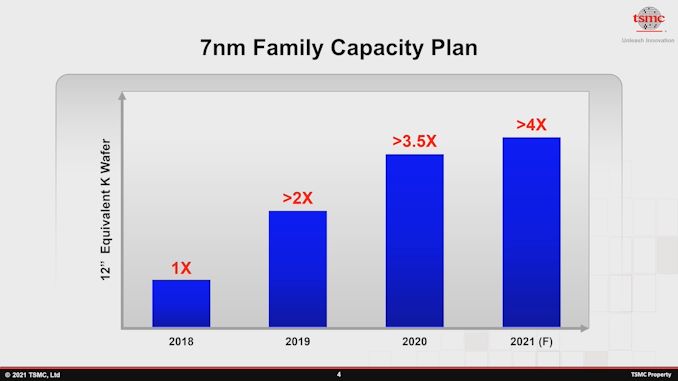
As projeções de capacidade previstas para 2021 incluem apenas um aumento de 14% na capacidade da família de 7 nm - começando em um ritmo lento que provavelmente imitará a progressão da capacidade da fundição para a família de processo de 16 nm mais antiga.
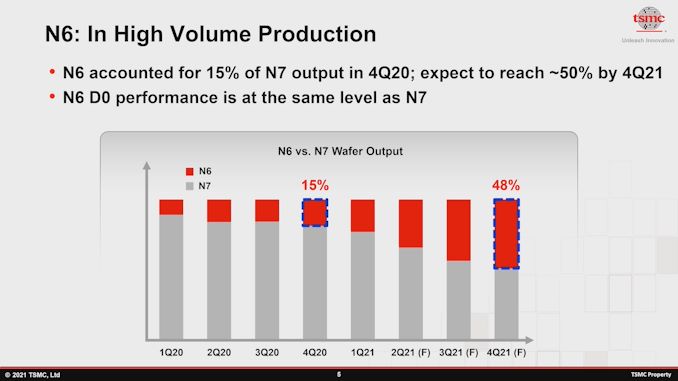
Embora muitos clientes estejam mudando para 5 nm e menos, a família de 7 nm permanecerá muito significativa em termos de receita, capacidade de produção e valor para o cliente. O nó N6 é um projeto evolutivo das variações anteriores do nó N7 e simplifica as etapas de fabricação ao introduzir o uso leve de camadas EUV.
O que tem sido extremamente surpreendente de ver é a taxa de adoção do N6 e como ele está substituindo o volume de fabricação do N7: No 4T20, o nó N6 representou apenas 15% de toda a capacidade de fabricação da família de 7 nm, enquanto se espera que chegue a 48-50% um ano depois, no 4T21. Isso significa que, enquanto conversamos, estamos vendo muitas novas rampas de novos produtos N6 de alto volume, o que é bastante interessante. Os suspeitos do costume seriam fornecedores como MediaTek e seus mais novos Dimensity SoCs , mas também vimos a Qualcomm revelar designs de SoC de médio alcance de 6 nm , como o Snapdragon 778G . Ainda não ouvimos sobre a produção do N6 de fornecedores de PC ou HPC, mas, devido ao grande aumento de volume, pode-se muito bem imaginar que deve haver alguns novos produtos também nesses setores da indústria.
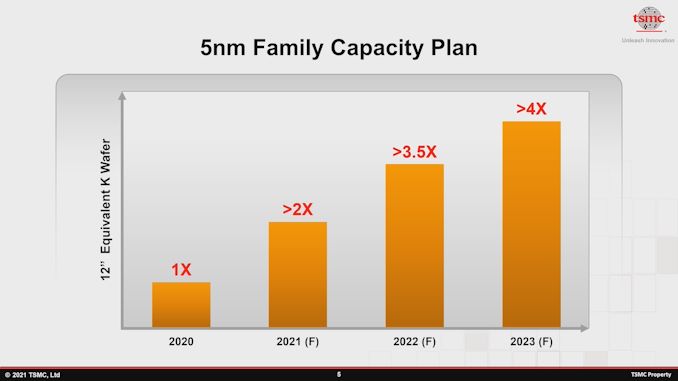
Para todo o ano de 2021, a TSMC espera dobrar rapidamente em sua capacidade de wafer de 2020, e aumentar ainda mais em 75% em 2022. Em 2023, a empresa prevê uma quadruplicação da capacidade de 2020, e isso ainda ocorrerá antes dos novos 5nm da empresa A fábrica do Arizona está programada para entrar em operação e adicionar mais 20 mil wafers / mês de capacidade.
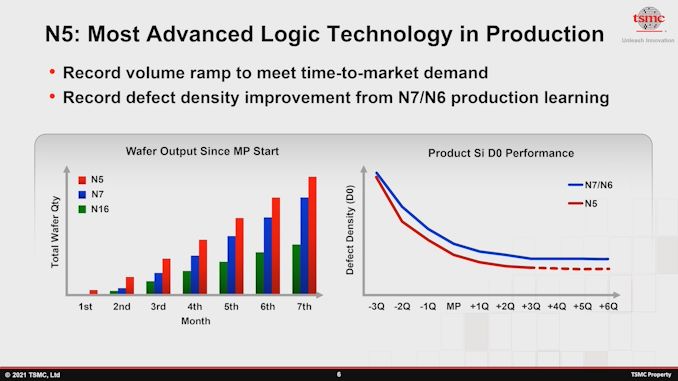
A rampa N5 da TSMC está indo extremamente bem e, conforme relatado no Simpósio de Tecnologia do ano passado , atingiu rendimentos melhores do que os nós de tecnologia de processo da família de 7nm jamais alcançaram. A empresa aqui aponta amplamente para etapas de fabricação simplificadas graças ao uso mais extensivo de camadas EUV em comparação com seus nós DUV e EUV de 7 nm. Em uma indústria onde a concorrência está lutando para aumentar os rendimentos nos mais recentes nós de ponta, isso é realmente um feito surpreendente da TSMC, que deve consolidar ainda mais o domínio atual da fundição.
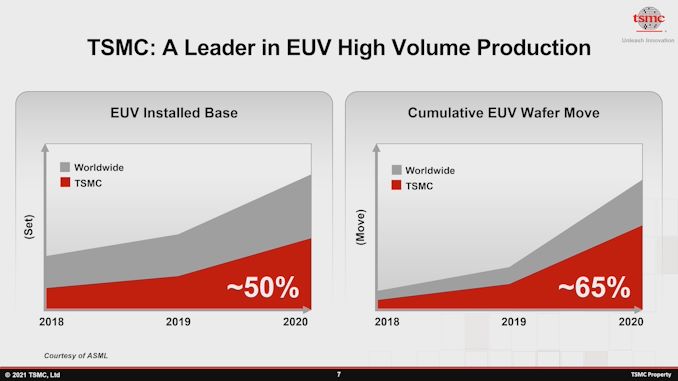
A fundição está bem ciente desse fato e orgulhosamente demonstra sua habilidade técnica por meio de uma métrica extremamente interessante: Embora a TSMC "apenas" tenha 50% da base instalada mundial de máquinas EUV, a empresa na verdade representa 65% das wafers EUV cumulativos enviados, o que significa que está fazendo um uso muito mais eficaz de sua capacidade de instalação.
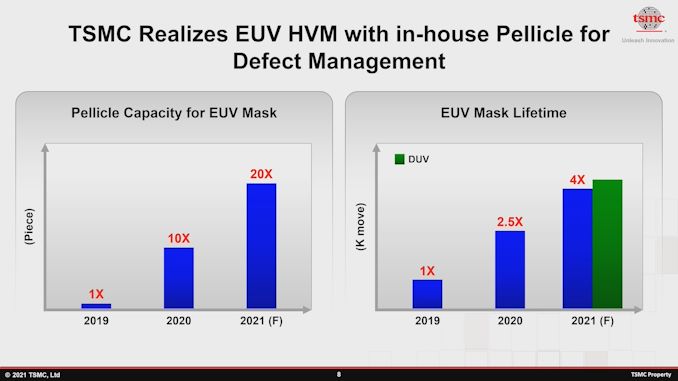
A TSMC afirma que está usando uma película desenvolvida internamente para seus nós EUV desde 2019 e mais extensivamente em 2020. Em comparação, a ASML e a Mitsui Chemicals anunciaram recentemente que planejam apenas iniciar as vendas em volume de sua própria película no 2T21, essencialmente agora na época deste artigo. A TSMC não declara nenhum detalhe técnico de sua película interna, mas se os rendimentos de N5 devem ser um sinal dos resultados, então deve ser uma parte importante do sucesso atual da TSMC em nós de ponta.
A empresa também observou que está melhorando continuamente a vida útil da máscara EUV - ou seja, a quantidade de tempo que uma máscara pode ser usada antes de ser substituída ou reparada, apontando que está prevendo que alcançará aproximadamente a vida útil da máscara DUV em 2021 Em outras palavras, isso significa que até agora, as máscaras EUV tinham uma vida útil notavelmente pior, o que resultaria em menos processamento de fabricação devido ao tempo de inatividade.

A empresa afirma que o N4 promete uma melhoria de densidade de 6% em relação ao N5, alcançada por meio de reduções ópticas da lógica, melhorias da biblioteca de células padrão e impulsos de regras de design para uso de área mais restrita. Afirma-se que veremos menor complexidade do processo de fabricação por meio da redução das máscaras, embora não detalhando as mudanças exatas.
N4, representando mudanças iterativas menores, tem o benefício de que os rendimentos são essencialmente pegando onde N5 está rastreando atualmente. Esse fato, junto com a complexidade do processo simplificado, indicaria amplamente que o N4 poderia muito bem representar uma mudança semelhante do N5 que o N6 está passando atualmente em relação ao N7, com muitos clientes mudando o novo nó aprimorado.
Estaremos cobrindo mais sobre o Simpósio de Tecnologia 2021 da TSMC nos próximos dias, à medida que escrevemos as coisas, incluindo mais detalhes sobre N3 e nós futuros, como N2 e além - então, fique atento.
7nm
6nm
5nm
4nm
3nm
Capacidade de 5 nm da TSMC para quadruplicar até 2023, a partir de 2020
ZEN 4 e RDNA 3 serão produzidos em 5nm, portanto é esperado que a AMD não tenha problemas de produção desses chip's
"TSMC diz que a construção da fábrica de chips do Arizona começou
TSMC says has begun construction at its Arizona chip factory site
Taiwan Semiconductor Manufacturing Co Ltd (2330.TW) (TSMC) has started construction at a site in Arizona where it plans to spend $12 billion to build a computer chip factory, its chief executive said on Tuesday.
www.reuters.com
Atualização de fabricação da TSMC: N6 para combinar com a saída N7 por EOY, N5 rampa mais rápido, melhores rendimentos do que N7

Alguns destaques:
- Capacidade de 5 nm para quadruplicar até 2023 em 2020
- A rampa N5 da TSMC está indo extremamente bem e, conforme relatado no Simpósio de Tecnologia do ano passado, atingiu rendimentos melhores do que os nós de tecnologia de processo da família de 7nm já alcançaram. A empresa aqui aponta amplamente para etapas de fabricação simplificadas graças ao uso mais extensivo de camadas EUV em comparação com seus nós DUV e EUV de 7 nm.
- No 4T20, o nó N6 representava apenas 15% de toda a capacidade de fabricação da família de 7 nm, enquanto se espera que chegue a 48-50% um ano depois, no 4T21.
- Embora a TSMC “apenas” tenha 50% da base instalada mundial de máquinas EUV, a empresa na verdade representa 65% da participação cumulativa das bolachas EUV enviadas, o que significa que está fazendo um uso muito mais eficaz de sua capacidade instalada.
- A TSMC afirma que está usando uma película desenvolvida internamente para seus nós EUV desde 2019 e mais extensivamente em 2020. A empresa também observou que está melhorando continuamente a vida útil da máscara EUV - ou seja, a quantidade de tempo que uma máscara pode ser usada antes de para ser substituído ou reparado, apontando que está previsto que aproximadamente alcançará o tempo de vida da máscara DUV em 2021. Em outras palavras, isso significa que até agora, as máscaras EUV tinham uma vida útil notavelmente pior, o que resultaria em menos produção devido ao tempo de inatividade.
- A empresa afirma que o N4 promete uma melhoria de densidade de 6% em relação ao N5, obtido por meio de reduções ópticas da lógica, melhorias da biblioteca de células padrão e impulsos de regra de design para uso de área mais restrita. Afirma-se que veremos menor complexidade do processo de fabricação por meio da redução de máscaras.
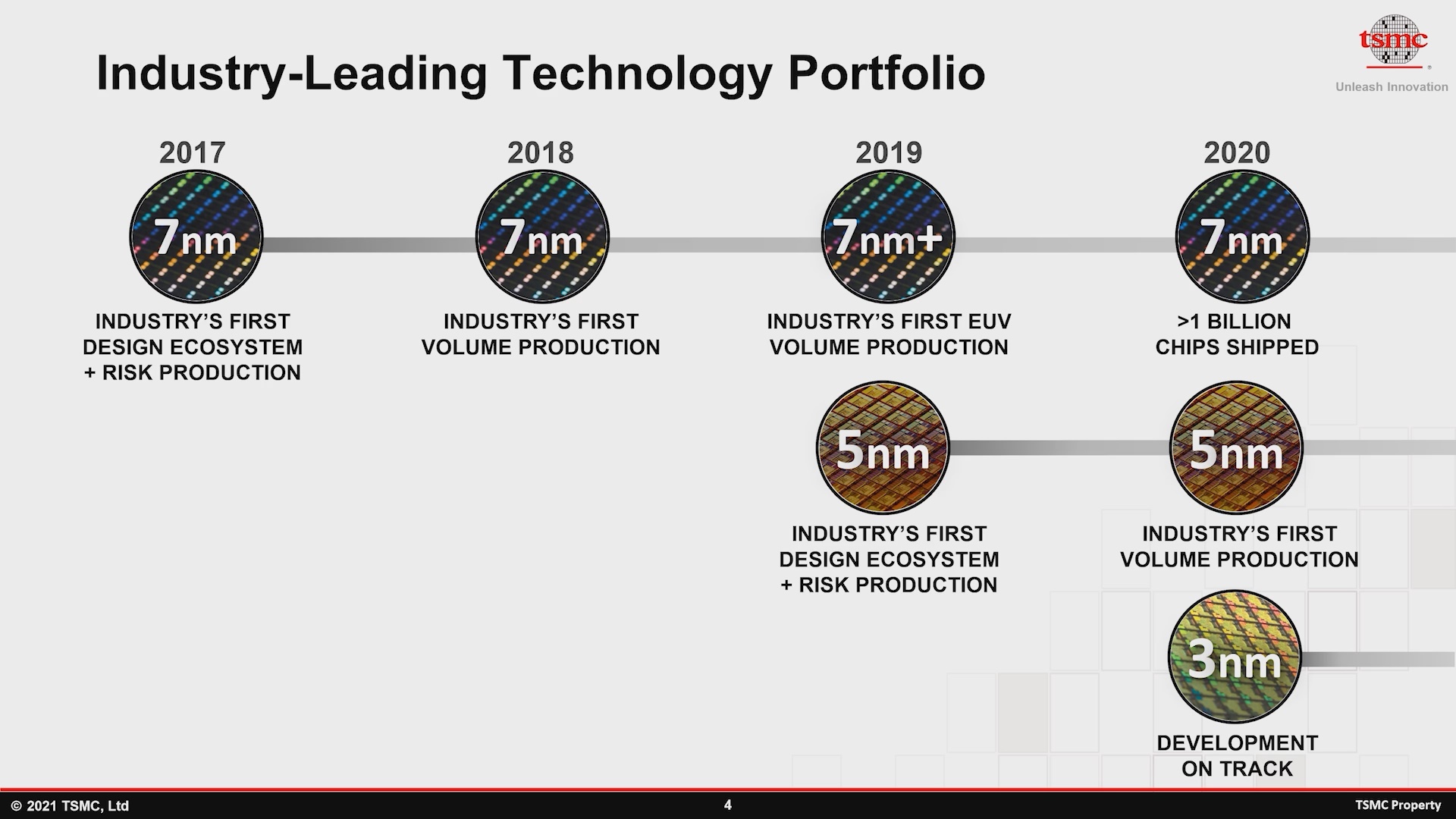
A TSMC separa seus nós de manufatura de ponta em três “famílias” de produtos: 7nm, 5nm e o próximo nó de manufatura de 3nm. Como muitos terão notado por meio de uma ampla gama de produtos ao longo dos últimos dois anos, a introdução do nó de 7 nm e a fabricação em massa da TSMC a partir de 2018 foi um verdadeiro tour de force para a fundição, conquistando uma liderança significativa na indústria em relação aos concorrentes mais próximos têm lutado para acompanhar até hoje.
Até o momento, a TSMC já despachou mais de 1 bilhão de chips de 7nm e a família de 7nm é considerada extremamente madura, com a fundição agora se concentrando em aumentar produtos de 5nm e próximos nós avançados de 3nm.
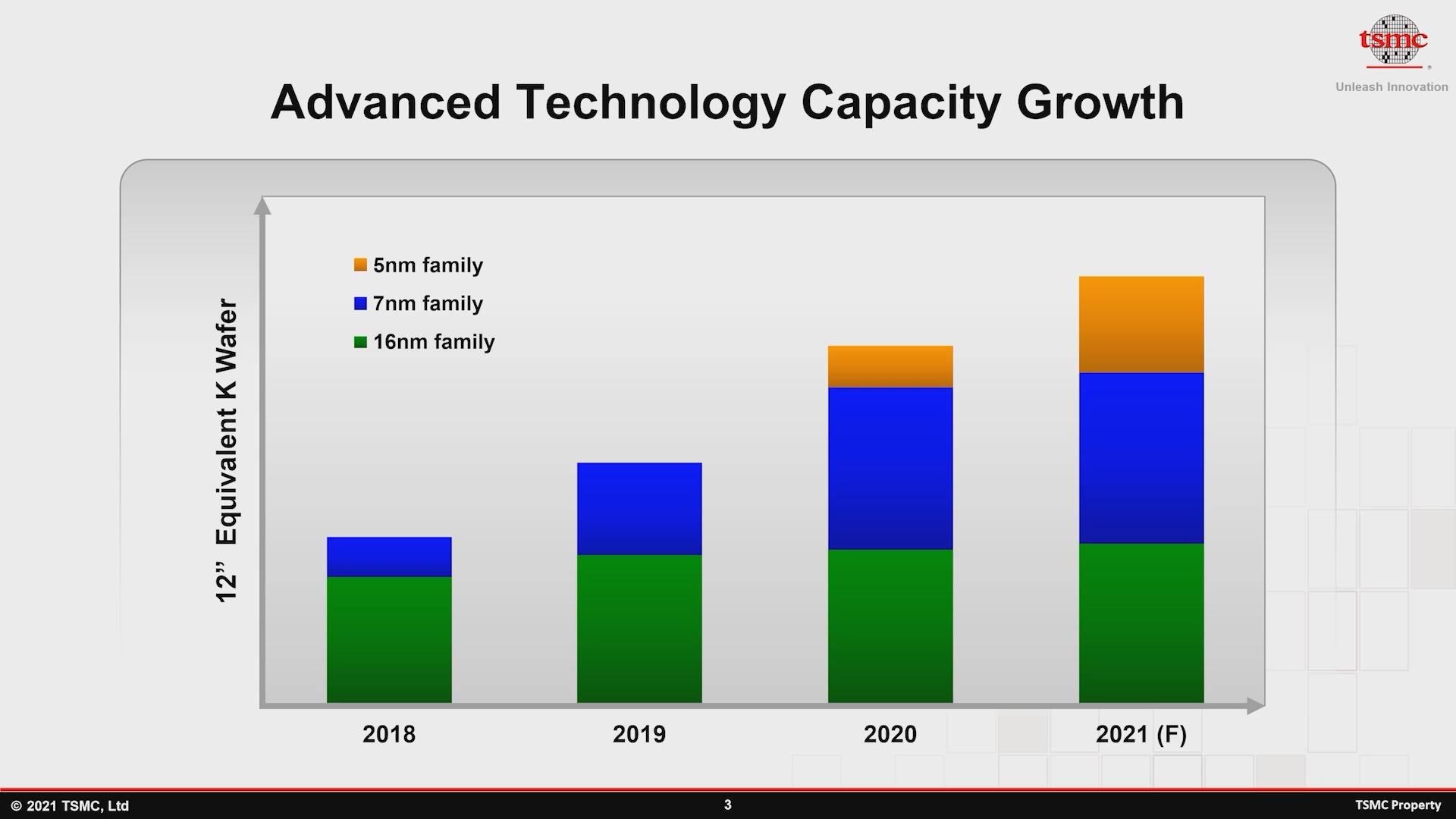
Em termos de capacidade da família de 7 nm, começando em 2021, a capacidade anual instalada está realmente começando a diminuir significativamente à medida que muitos clientes migram para os nós de processo mais avançados.

As projeções de capacidade previstas para 2021 incluem apenas um aumento de 14% na capacidade da família de 7 nm - começando em um ritmo lento que provavelmente imitará a progressão da capacidade da fundição para a família de processo de 16 nm mais antiga.

Embora muitos clientes estejam mudando para 5 nm e menos, a família de 7 nm permanecerá muito significativa em termos de receita, capacidade de produção e valor para o cliente. O nó N6 é um projeto evolutivo das variações anteriores do nó N7 e simplifica as etapas de fabricação ao introduzir o uso leve de camadas EUV.
O que tem sido extremamente surpreendente de ver é a taxa de adoção do N6 e como ele está substituindo o volume de fabricação do N7: No 4T20, o nó N6 representou apenas 15% de toda a capacidade de fabricação da família de 7 nm, enquanto se espera que chegue a 48-50% um ano depois, no 4T21. Isso significa que, enquanto conversamos, estamos vendo muitas novas rampas de novos produtos N6 de alto volume, o que é bastante interessante. Os suspeitos do costume seriam fornecedores como MediaTek e seus mais novos Dimensity SoCs , mas também vimos a Qualcomm revelar designs de SoC de médio alcance de 6 nm , como o Snapdragon 778G . Ainda não ouvimos sobre a produção do N6 de fornecedores de PC ou HPC, mas, devido ao grande aumento de volume, pode-se muito bem imaginar que deve haver alguns novos produtos também nesses setores da indústria.
Capacidade de 5 nm para quadruplicar até 2023, a partir de 2020
O nó de processo de 5nm da TSMC está em produção em massa desde 2020 e, notavelmente, alimenta centenas de milhões de novos SoCs alimentando os chips A14 da Apple na série iPhone 12 , bem como o novo chip M1 Mac . Embora a HiSilicon fosse um cliente líder da TSMC a 5 nm, a TSMC interrompeu toda a produção da empresa em setembro devido a restrições comerciais. A TSMC atualiza hoje que enviou 500k wafers N5, o que representaria cerca de algumas centenas de milhões de chips. Embora isso leve à Apple essencialmente tendo uma espécie de exclusividade para o nó N5 em 2020, conforme mais empresas estão começando a aumentar seus produtos de 5 nm, a TSMC precisará aumentar muito mais capacidade de produção, na qual a empresa está investindo pesadamente:
Para todo o ano de 2021, a TSMC espera dobrar rapidamente em sua capacidade de wafer de 2020, e aumentar ainda mais em 75% em 2022. Em 2023, a empresa prevê uma quadruplicação da capacidade de 2020, e isso ainda ocorrerá antes dos novos 5nm da empresa A fábrica do Arizona está programada para entrar em operação e adicionar mais 20 mil wafers / mês de capacidade.
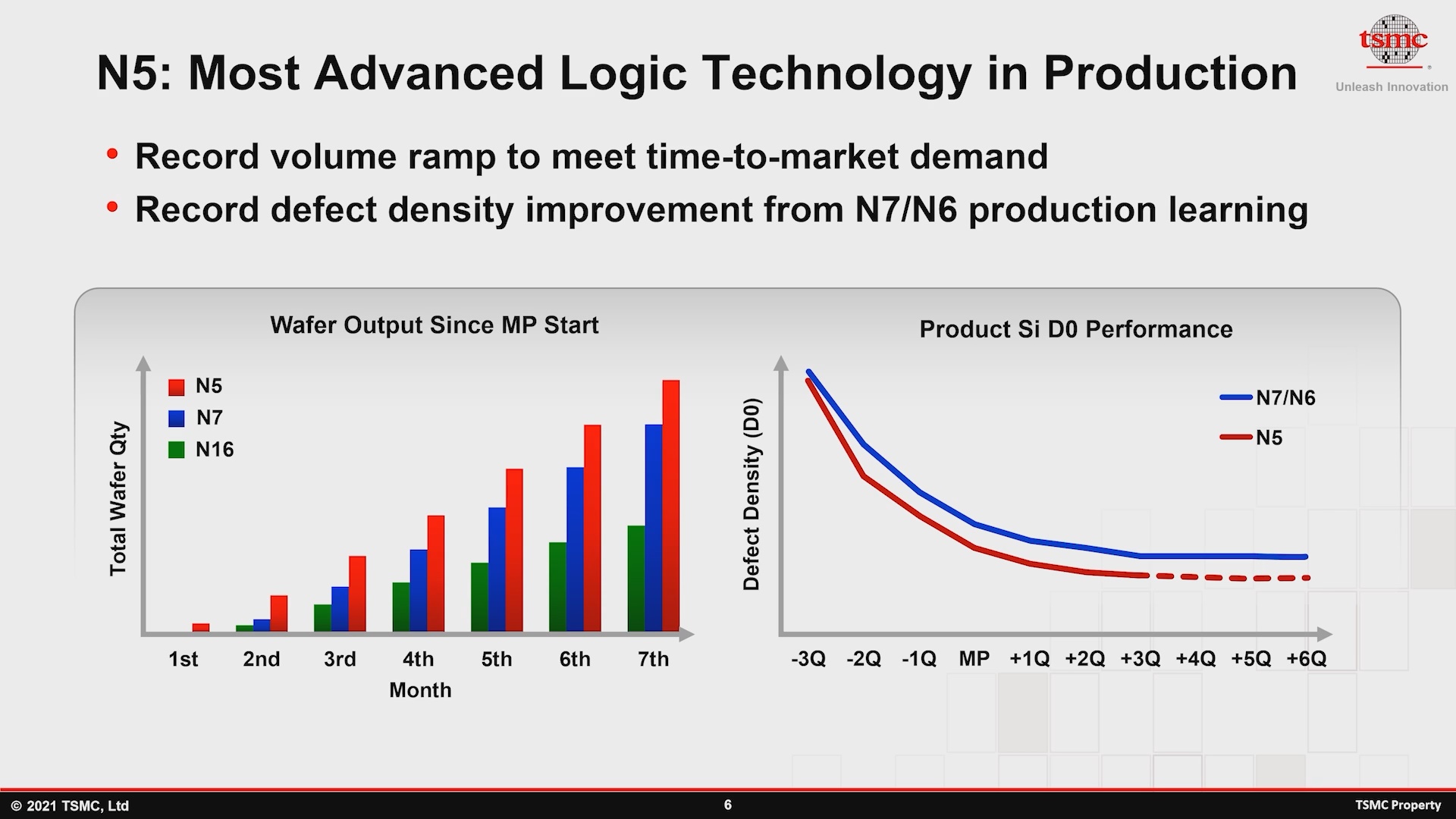
A rampa N5 da TSMC está indo extremamente bem e, conforme relatado no Simpósio de Tecnologia do ano passado , atingiu rendimentos melhores do que os nós de tecnologia de processo da família de 7nm jamais alcançaram. A empresa aqui aponta amplamente para etapas de fabricação simplificadas graças ao uso mais extensivo de camadas EUV em comparação com seus nós DUV e EUV de 7 nm. Em uma indústria onde a concorrência está lutando para aumentar os rendimentos nos mais recentes nós de ponta, isso é realmente um feito surpreendente da TSMC, que deve consolidar ainda mais o domínio atual da fundição.
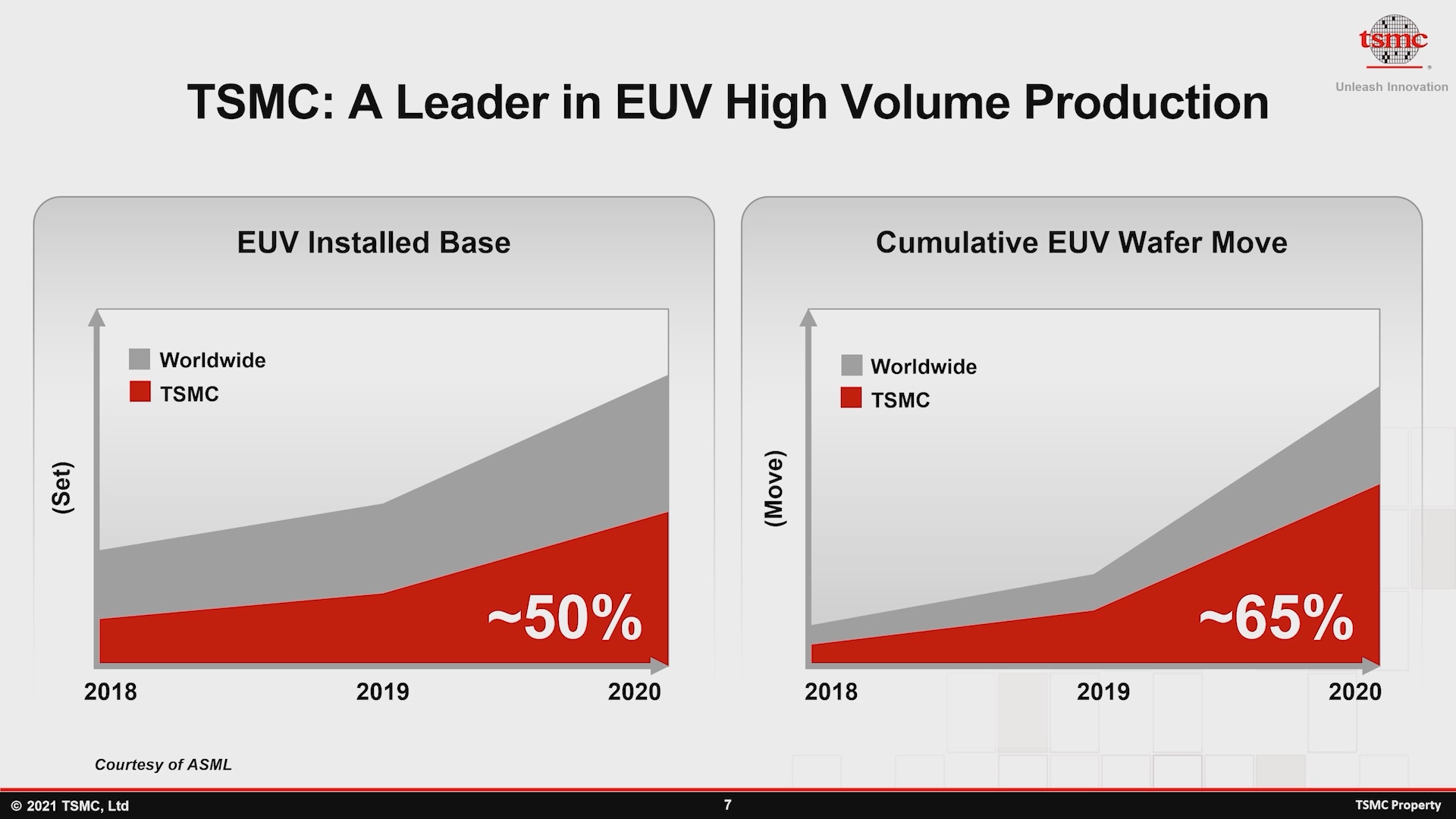
A fundição está bem ciente desse fato e orgulhosamente demonstra sua habilidade técnica por meio de uma métrica extremamente interessante: Embora a TSMC "apenas" tenha 50% da base instalada mundial de máquinas EUV, a empresa na verdade representa 65% das wafers EUV cumulativos enviados, o que significa que está fazendo um uso muito mais eficaz de sua capacidade de instalação.
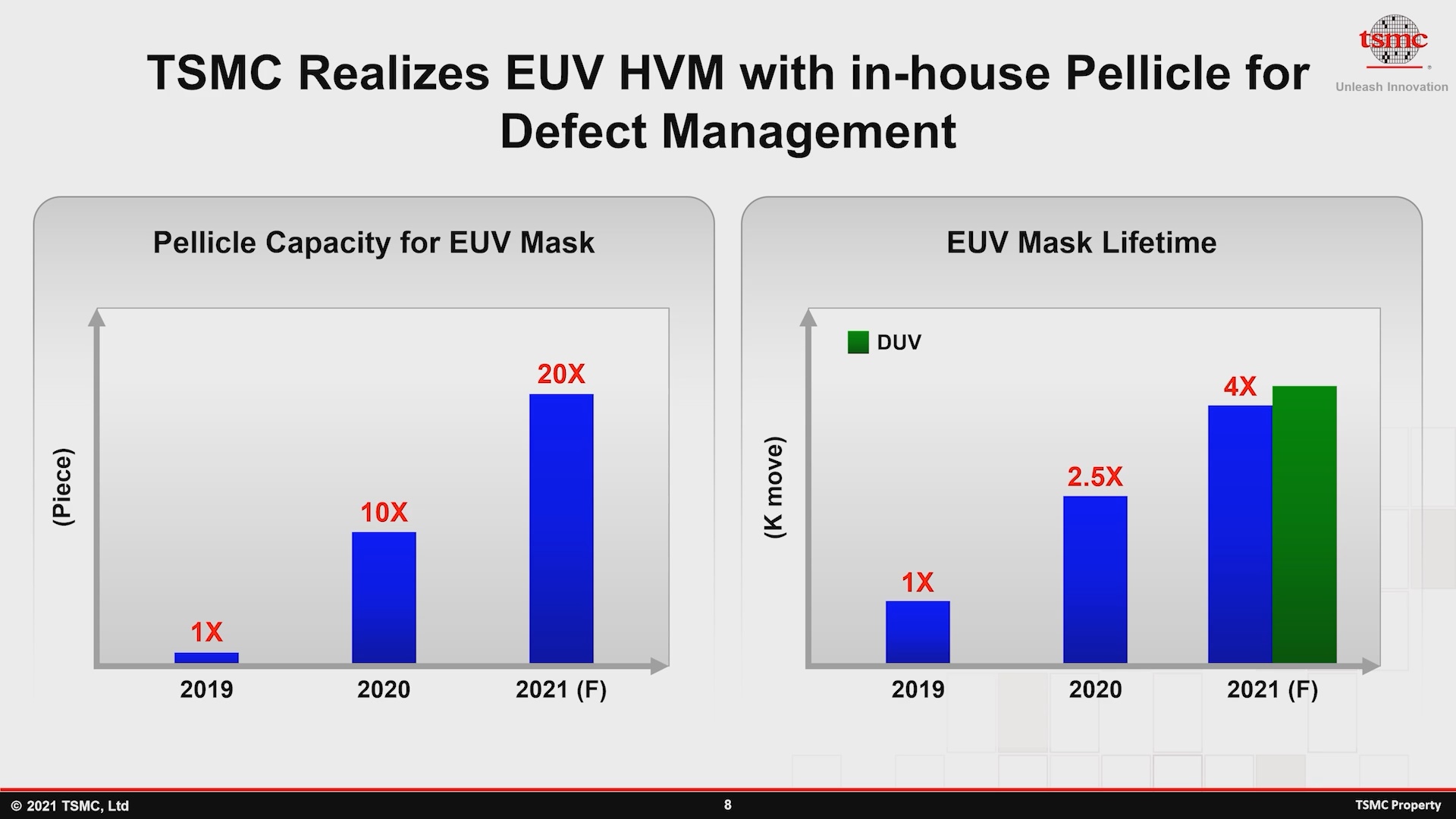
A TSMC afirma que está usando uma película desenvolvida internamente para seus nós EUV desde 2019 e mais extensivamente em 2020. Em comparação, a ASML e a Mitsui Chemicals anunciaram recentemente que planejam apenas iniciar as vendas em volume de sua própria película no 2T21, essencialmente agora na época deste artigo. A TSMC não declara nenhum detalhe técnico de sua película interna, mas se os rendimentos de N5 devem ser um sinal dos resultados, então deve ser uma parte importante do sucesso atual da TSMC em nós de ponta.
A empresa também observou que está melhorando continuamente a vida útil da máscara EUV - ou seja, a quantidade de tempo que uma máscara pode ser usada antes de ser substituída ou reparada, apontando que está prevendo que alcançará aproximadamente a vida útil da máscara DUV em 2021 Em outras palavras, isso significa que até agora, as máscaras EUV tinham uma vida útil notavelmente pior, o que resultaria em menos processamento de fabricação devido ao tempo de inatividade.
N4: Pequeno encolhimento óptico de N5
O nó N4 da TSMC é um caminho de migração bastante direto do N5, aproveitando melhorias iterativas no processo.
A empresa afirma que o N4 promete uma melhoria de densidade de 6% em relação ao N5, alcançada por meio de reduções ópticas da lógica, melhorias da biblioteca de células padrão e impulsos de regras de design para uso de área mais restrita. Afirma-se que veremos menor complexidade do processo de fabricação por meio da redução das máscaras, embora não detalhando as mudanças exatas.
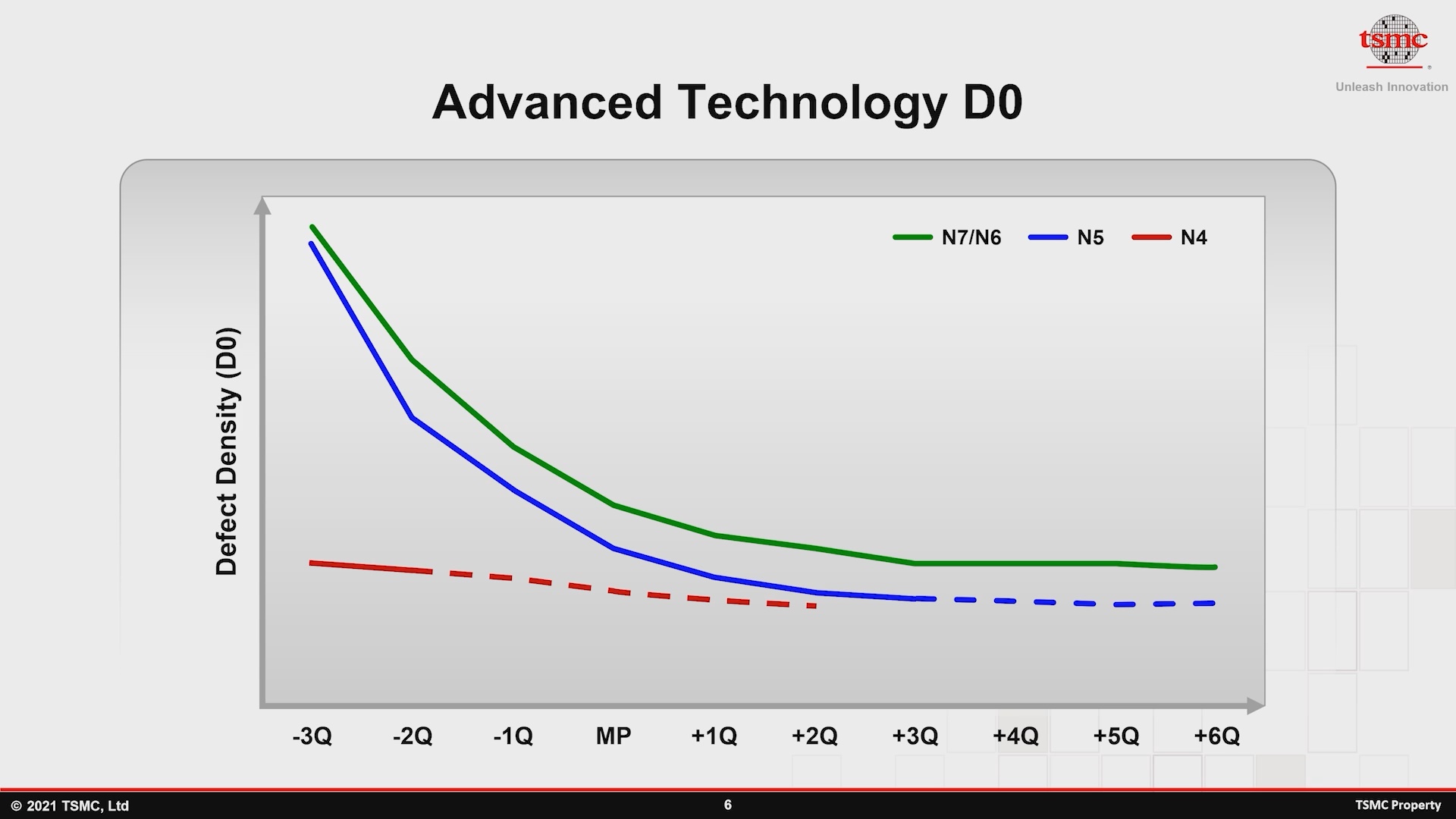
N4, representando mudanças iterativas menores, tem o benefício de que os rendimentos são essencialmente pegando onde N5 está rastreando atualmente. Esse fato, junto com a complexidade do processo simplificado, indicaria amplamente que o N4 poderia muito bem representar uma mudança semelhante do N5 que o N6 está passando atualmente em relação ao N7, com muitos clientes mudando o novo nó aprimorado.
Estaremos cobrindo mais sobre o Simpósio de Tecnologia 2021 da TSMC nos próximos dias, à medida que escrevemos as coisas, incluindo mais detalhes sobre N3 e nós futuros, como N2 e além - então, fique atento.
Última edição:
Boas novidades para o AMD ZEN, relacionado a TSMC de forma indireta
7nm
6nm
5nm
4nm
3nm
Capacidade de 5 nm da TSMC para quadruplicar até 2023, a partir de 2020
ZEN 4 e RDNA 3 serão produzidos em 5nm, portanto é esperado que a AMD não tenha problemas de produção desses chip's
"TSMC diz que a construção da fábrica de chips do Arizona começou
TSMC says has begun construction at its Arizona chip factory site
Taiwan Semiconductor Manufacturing Co Ltd (2330.TW) (TSMC) has started construction at a site in Arizona where it plans to spend $12 billion to build a computer chip factory, its chief executive said on Tuesday.
Atualização de fabricação da TSMC: N6 para combinar com a saída N7 por EOY, N5 rampa mais rápido, melhores rendimentos do que N7
Alguns destaques:
No TSMC Technology Symposium deste ano, a empresa aproveitou a oportunidade para atualizar seus clientes e observadores da indústria sobre os últimos desenvolvimentos do fabricante de semicondutores em relação às suas mais novas tecnologias e roteiros de fabricação. Como parte de uma apresentação regular, a fundição nos atualizou sobre seu status em suas atuais tecnologias de fabricação de ponta, o N7, N5 e seus respectivos derivados, como N6 e N5.
- Capacidade de 5 nm para quadruplicar até 2023 em 2020
- A rampa N5 da TSMC está indo extremamente bem e, conforme relatado no Simpósio de Tecnologia do ano passado, atingiu rendimentos melhores do que os nós de tecnologia de processo da família de 7nm já alcançaram. A empresa aqui aponta amplamente para etapas de fabricação simplificadas graças ao uso mais extensivo de camadas EUV em comparação com seus nós DUV e EUV de 7 nm.
- No 4T20, o nó N6 representava apenas 15% de toda a capacidade de fabricação da família de 7 nm, enquanto se espera que chegue a 48-50% um ano depois, no 4T21.
- Embora a TSMC “apenas” tenha 50% da base instalada mundial de máquinas EUV, a empresa na verdade representa 65% da participação cumulativa das bolachas EUV enviadas, o que significa que está fazendo um uso muito mais eficaz de sua capacidade instalada.
- A TSMC afirma que está usando uma película desenvolvida internamente para seus nós EUV desde 2019 e mais extensivamente em 2020. A empresa também observou que está melhorando continuamente a vida útil da máscara EUV - ou seja, a quantidade de tempo que uma máscara pode ser usada antes de para ser substituído ou reparado, apontando que está previsto que aproximadamente alcançará o tempo de vida da máscara DUV em 2021. Em outras palavras, isso significa que até agora, as máscaras EUV tinham uma vida útil notavelmente pior, o que resultaria em menos produção devido ao tempo de inatividade.
- A empresa afirma que o N4 promete uma melhoria de densidade de 6% em relação ao N5, obtido por meio de reduções ópticas da lógica, melhorias da biblioteca de células padrão e impulsos de regra de design para uso de área mais restrita. Afirma-se que veremos menor complexidade do processo de fabricação por meio da redução de máscaras.
A TSMC separa seus nós de manufatura de ponta em três “famílias” de produtos: 7nm, 5nm e o próximo nó de manufatura de 3nm. Como muitos terão notado por meio de uma ampla gama de produtos ao longo dos últimos dois anos, a introdução do nó de 7 nm e a fabricação em massa da TSMC a partir de 2018 foi um verdadeiro tour de force para a fundição, conquistando uma liderança significativa na indústria em relação aos concorrentes mais próximos têm lutado para acompanhar até hoje.
Até o momento, a TSMC já despachou mais de 1 bilhão de chips de 7nm e a família de 7nm é considerada extremamente madura, com a fundição agora se concentrando em aumentar produtos de 5nm e próximos nós avançados de 3nm.
Em termos de capacidade da família de 7 nm, começando em 2021, a capacidade anual instalada está realmente começando a diminuir significativamente à medida que muitos clientes migram para os nós de processo mais avançados.
As projeções de capacidade previstas para 2021 incluem apenas um aumento de 14% na capacidade da família de 7 nm - começando em um ritmo lento que provavelmente imitará a progressão da capacidade da fundição para a família de processo de 16 nm mais antiga.
Embora muitos clientes estejam mudando para 5 nm e menos, a família de 7 nm permanecerá muito significativa em termos de receita, capacidade de produção e valor para o cliente. O nó N6 é um projeto evolutivo das variações anteriores do nó N7 e simplifica as etapas de fabricação ao introduzir o uso leve de camadas EUV.
O que tem sido extremamente surpreendente de ver é a taxa de adoção do N6 e como ele está substituindo o volume de fabricação do N7: No 4T20, o nó N6 representou apenas 15% de toda a capacidade de fabricação da família de 7 nm, enquanto se espera que chegue a 48-50% um ano depois, no 4T21. Isso significa que, enquanto conversamos, estamos vendo muitas novas rampas de novos produtos N6 de alto volume, o que é bastante interessante. Os suspeitos do costume seriam fornecedores como MediaTek e seus mais novos Dimensity SoCs , mas também vimos a Qualcomm revelar designs de SoC de médio alcance de 6 nm , como o Snapdragon 778G . Ainda não ouvimos sobre a produção do N6 de fornecedores de PC ou HPC, mas, devido ao grande aumento de volume, pode-se muito bem imaginar que deve haver alguns novos produtos também nesses setores da indústria.
Capacidade de 5 nm para quadruplicar até 2023, a partir de 2020
O nó de processo de 5nm da TSMC está em produção em massa desde 2020 e, notavelmente, alimenta centenas de milhões de novos SoCs alimentando os chips A14 da Apple na série iPhone 12 , bem como o novo chip M1 Mac . Embora a HiSilicon fosse um cliente líder da TSMC a 5 nm, a TSMC interrompeu toda a produção da empresa em setembro devido a restrições comerciais. A TSMC atualiza hoje que enviou 500k wafers N5, o que representaria cerca de algumas centenas de milhões de chips. Embora isso leve à Apple essencialmente tendo uma espécie de exclusividade para o nó N5 em 2020, conforme mais empresas estão começando a aumentar seus produtos de 5 nm, a TSMC precisará aumentar muito mais capacidade de produção, na qual a empresa está investindo pesadamente:
Para todo o ano de 2021, a TSMC espera dobrar rapidamente em sua capacidade de wafer de 2020, e aumentar ainda mais em 75% em 2022. Em 2023, a empresa prevê uma quadruplicação da capacidade de 2020, e isso ainda ocorrerá antes dos novos 5nm da empresa A fábrica do Arizona está programada para entrar em operação e adicionar mais 20 mil wafers / mês de capacidade.
A rampa N5 da TSMC está indo extremamente bem e, conforme relatado no Simpósio de Tecnologia do ano passado , atingiu rendimentos melhores do que os nós de tecnologia de processo da família de 7nm jamais alcançaram. A empresa aqui aponta amplamente para etapas de fabricação simplificadas graças ao uso mais extensivo de camadas EUV em comparação com seus nós DUV e EUV de 7 nm. Em uma indústria onde a concorrência está lutando para aumentar os rendimentos nos mais recentes nós de ponta, isso é realmente um feito surpreendente da TSMC, que deve consolidar ainda mais o domínio atual da fundição.
A fundição está bem ciente desse fato e orgulhosamente demonstra sua habilidade técnica por meio de uma métrica extremamente interessante: Embora a TSMC "apenas" tenha 50% da base instalada mundial de máquinas EUV, a empresa na verdade representa 65% das wafers EUV cumulativos enviados, o que significa que está fazendo um uso muito mais eficaz de sua capacidade de instalação.
A TSMC afirma que está usando uma película desenvolvida internamente para seus nós EUV desde 2019 e mais extensivamente em 2020. Em comparação, a ASML e a Mitsui Chemicals anunciaram recentemente que planejam apenas iniciar as vendas em volume de sua própria película no 2T21, essencialmente agora na época deste artigo. A TSMC não declara nenhum detalhe técnico de sua película interna, mas se os rendimentos de N5 devem ser um sinal dos resultados, então deve ser uma parte importante do sucesso atual da TSMC em nós de ponta.
A empresa também observou que está melhorando continuamente a vida útil da máscara EUV - ou seja, a quantidade de tempo que uma máscara pode ser usada antes de ser substituída ou reparada, apontando que está prevendo que alcançará aproximadamente a vida útil da máscara DUV em 2021 Em outras palavras, isso significa que até agora, as máscaras EUV tinham uma vida útil notavelmente pior, o que resultaria em menos processamento de fabricação devido ao tempo de inatividade.
N4: Pequeno encolhimento óptico de N5
O nó N4 da TSMC é um caminho de migração bastante direto do N5, aproveitando melhorias iterativas no processo.
A empresa afirma que o N4 promete uma melhoria de densidade de 6% em relação ao N5, alcançada por meio de reduções ópticas da lógica, melhorias da biblioteca de células padrão e impulsos de regras de design para uso de área mais restrita. Afirma-se que veremos menor complexidade do processo de fabricação por meio da redução das máscaras, embora não detalhando as mudanças exatas.
N4, representando mudanças iterativas menores, tem o benefício de que os rendimentos são essencialmente pegando onde N5 está rastreando atualmente. Esse fato, junto com a complexidade do processo simplificado, indicaria amplamente que o N4 poderia muito bem representar uma mudança semelhante do N5 que o N6 está passando atualmente em relação ao N7, com muitos clientes mudando o novo nó aprimorado.
Estaremos cobrindo mais sobre o Simpósio de Tecnologia 2021 da TSMC nos próximos dias, à medida que escrevemos as coisas, incluindo mais detalhes sobre N3 e nós futuros, como N2 e além - então, fique atento.
@RHBH
Comprei mais ações da TSMC hoje de manhã, estou feliz

Sua placa mãe é uma Steel Legend b450?
Tem acontecido algo semelhante aqui com o meu 2700 non-x, mas o detalhe é que aqui dá tela azul, sem estar jogando e principalmente, com temperaturas estáveis (uso WC a cpu em idle/load para atividades leves não passa de 45°c)
Não, é uma MSI b450 gaming plus.
Eu vou testar, o meu deixei tudo no automático.VDDG CCD e VDDG IOD não devem exceder o VSOC.
Sugiro manter 0.05v de diferença entre eles 1.10v no VDDG me parece demasiado para FLCK 1866.
Recomendo testar estes valores:
VSOC: 1.125v
VDDG IOD: 1.05v
VDDG CCD: 1.00v
É um nvme Xpg gammix s11l(gammix s5 remarcado aparentemente), o windows tá instalado nele. Ele é dram-less mas tem aquele recurso hmb, fico pensando se o fato de usar a ram do sistema como cache contribui para aumentar as latencias. O sistema não tá lento, mas noto que ele é um pouquinho arrastado aqui e a ali, pode ser o windows que a cada atualização parece que fica menos responsivo.Me parece tudo normal. Qual seu SSD?
Já em jogos, quase todos percebo alguns engasguinhos, ai olho o frametime e tem spikes altos, acredito que na hora de carregar assets do disco para ram, isso no gammix s11l nvme, adata580 sata(novinho) e hdd(westernblue). Alguns exemplos.
Days Gone(adata sp580):
Divinity Original Sin 2(adata sp580):
Cyberpunk2007(gammix s11l):
Eu testei o cyberpunk limitando em 60fps pelo FRC do driver da amd, parece que os spikes foram maiores que limitando a 60fps pelo AMD chill. Vsync desabilitado em ambos os casos, meu monitor tem freesync.
O jogo com pior caso disso aqui foi W3, mesmo no ssd da uns engasgos durante streaming e os spikes ficam acima de 50ms, ja vi até passar de 100ms. O melhor acho que é o GTAV que o frametime fica quase todo plano instalado no hdd.
Achei que a causa pudesse ser a RAM e latência com o ryzen 3600. Se eu tentar apertar os timings notarei diferença prática? Esse meu kit veio com samsung c-die que é bem ruim pelo que dizem, então não tem muito potencial para melhorar mais do que ja tá com xmp creio eu. Outra coisa, o perfil xmp dessas memorias em 3200mhz é 1.35v de tensão, porém o Aida64 exibe 1.36~1.38v, li que não é recomendado exceder 1.35 com c-die por questões de instabilidade e degradação do chip, essa pequena diferença pode causar problema?
Última edição:
AMD ROADMAP
7nm - ZEN 3 - RYZEN 5000
6nm - ZEN 3+ - MOBILE e HEDT
5nm - ZEN 4 - RYZEN 7000
4nm
3nm - ZEN 5 - RYZEN 8000
3nm - ZEN 5 + ZEN 4D - RYZEN 8000 APU





 videocardz.com
videocardz.com

 wccftech.com
wccftech.com

 adoredtv.com
adoredtv.com
A mídia decidiu reter a informação até que a confirmação de outras fontes esteja disponível, no entanto, ninguém mais foi capaz de confirmar os detalhes que foram mencionados nos slides, razão pela qual GamersNexus nunca os publicou. As coisas mudaram quando o ExecutableFix começou a liberar detalhes do Raphael / AM5 que estavam mais ou menos em alinhamento com o que a GN recebeu um ano atrás.
Este slide pode ser interessante por outro motivo, ele lista um suposto codinome de Warhol , que se acredita ser uma atualização do Zen3 de algum tipo:

Detalhes do AMD Raphael de março de 2022, Fonte: Gamers Nexus
Há, no entanto, alguma disparidade entre as novas informações e o que parece ser uma apresentação interna de 2020. Para começar, o TDP das novas CPUs Raphael deve ir mais alto, até 120 W, enquanto os slides antigos listavam até 105W TDP. O que pode certamente ser interessante é que os slides da GamersNexus também listam notebooks para jogos da série Raphael , o que não foi especulado antes. No momento, acredita-se que o Raphael será oferecido junto com o Phoenix APU, que também contará com a arquitetura central do Zen4.
Os slides também confirmam um codinome para Zen4 CCD, que é Durango . De acordo com este slide de 2020, Raphael apresentaria o Zen4 CCD feito na tecnologia de processo TSMC N5 e CIOD3 no processo N7 da TSMC . O slide também reafirma rumores anteriores de que o Raphel apresentaria gráficos integrados no chip , que seriam baseados no Navi2 oferecendo 'desempenho gráfico de desktop de nível básico'.
Outro slide mostrando o pacote AM5 apresenta detalhes sobre a configuração CIOD3 e CCD duplo Durango. Como diz o slide, o CCD secundário é opcional. No entanto, ele não mostra uma configuração de CCD triplo (que havia rumores de outras fontes). Além disso, também sugere que cada CCD tem até 8 núcleos e 16 threads, o que é mais uma confirmação de que a configuração do núcleo do CCD não teria mudado em comparação com o CCD do Zen3.
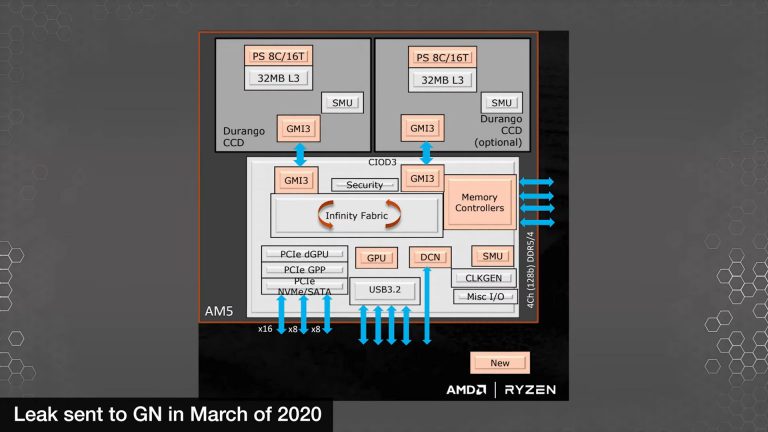
Detalhes do AMD AM5 de março de 2022, Fonte: Gamers Nexus
Outro slide mostra 'Raphael AM4 SOC'. Não está claro se isso se refere a um APU de baixa potência projetado com suporte a AM4 em mente (o que implicaria que o Raphel também poderia lançar para o soquete AM4 de alguma forma) ou simplesmente mostra informações incorretas ou desatualizadas. Independentemente desse fato, este slide também vai de encontro a um relatório recente de que o Raphel oferece suporte a até 28 pistas PCIe.

Informações do SoC AMD Raphael AM4 de março de 2022, Fonte: Gamers Nexus
Todos esses dados estão sendo comparados aos relatórios ExecutableFix recentes que revelaram o design do pacote AM5 (LGA1718) que está por vir e o dissipador de calor integrado do Raphael.
A ExecuFix deu um passo além e também revelou que Raphael suportaria apenas memória DDR5 (que novamente é ao contrário do slide acima listando apenas DDR4) e oferecerá TDP de até 170W (supostamente para um SKU de edição especial).
No momento, o AMD Raphel deve estrear no final de 2022. A AMD revelou na Computex que vai começar a produção de seus CPUs Zen3 baseados em V-Cache no início deste ano, o que sugere uma possível atualização do Zen3 no início de 2022. Isso pode servir como um interino atualize até que o Zen4 Raphael comece a funcionar.
 videocardz.com
videocardz.com
 videocardz.com
videocardz.com
O AMD Raphael teria um design muito mais sofisticado do que o esperado anteriormente. Não apenas o dissipador de calor integrado (IHS) para Raphael CPU não tem um design uniforme, mas supostamente também tem aberturas para capacitores. Esta é uma grande atualização em relação ao design IHS simples das CPUs AM4 Ryzen.


ExecutableFix havia revelado anteriormente que o pacote AM5 exigirá um soquete Land Grid Array (LGA), que substituiria os pinos da CPU do Zen3 por almofadas. Alguns usuários notaram que não havia capacitores na parte de trás do processador e não havia muito espaço no outro lado. Assim, foi especulado que esses capacitores poderiam estar escondidos sob o IHS ou nos interruptores ao redor do IHS. Este último foi provado correto, pelo menos está de acordo com o último vazamento do ExecuFix:


Hoje cobrimos um vazamento diferente do AM5 da Gamers Nexus , que obteve acesso a supostos slides internos da AMD confirmando os codinomes de Raphael e Warhol. Os dados apresentados não eram tão precisos quanto os relatórios do ExectuFix, mas esses slides são desatualizados e claramente houve uma mudança desde que foram feitos.
O AMD Raphael deve estrear no final de 2022 com núcleos Zen4 no soquete AM5 (LGA1178). Espera-se que essas séries de CPU apresentem suporte DDR5 exclusivamente e só irão suportar o padrão PCIe Gen4 no lançamento. Parte disso pode mudar com o tempo, à medida que a plataforma AM5 se torna mais popular à medida que a AMD lança mais CPUs para este novo soquete.
O novo design do Raphael IHS será perinatalmente um pesadelo terrível, no entanto, ainda não foi confirmado se as novas CPUs Zen4 são soldadas ao IHS como acontece com as CPUs Ryzen topo de linha atualmente.
@RHBH @nando3d
7nm - ZEN 3 - RYZEN 5000
6nm - ZEN 3+ - MOBILE e HEDT
5nm - ZEN 4 - RYZEN 7000
4nm
3nm - ZEN 5 - RYZEN 8000
3nm - ZEN 5 + ZEN 4D - RYZEN 8000 APU
A apresentação do AMD Raphael (Zen4 e AM5) de março de 2020 vazou
AMD Raphael (Zen4 & AM5) presentation from March 2020 leaks out - VideoCardz.com
AMD Raphael AM5 details leak out Gamers Nexus revealed alleged AMD internal slides they had received back in March 2020. Those slides feature details on AMD’s yet unannounced product codenamed Raphael, which is to be the first Zen4 based desktop CPUs series. The media has decided to withhold...
videocardz.com
Old AMD Ryzen 'Raphael' Zen 4 Desktop CPU & AM5 Platform Slides Leaked, Show Just How Much Has Changed Since 2020
In a new video published by Gamers Nexus, slides regarding AMD's Zen 4 powered Ryzen 'Raphael' and the AM5 platform have leaked out.
AMD EPYC Genoa Leak: 128 Cores, 16 CCDs, 12-Channel DDR5-5200, Die Sizes
Genoa with 128 cores, packing up to 16 CCDs with an IO die 37% smaller than Milan? Throw Milan-X X3D Stacking into the mix and you got a recipe for dominance in 2022.
Detalhes do AMD Raphael AM5 vazam
Os gamers Nexus revelaram supostos slides internos da AMD que receberam em março de 2020. Esses slides apresentam detalhes sobre o produto da AMD, ainda não anunciado, com o codinome Raphael, que será a primeira série de CPUs de desktop baseadas no Zen4.A mídia decidiu reter a informação até que a confirmação de outras fontes esteja disponível, no entanto, ninguém mais foi capaz de confirmar os detalhes que foram mencionados nos slides, razão pela qual GamersNexus nunca os publicou. As coisas mudaram quando o ExecutableFix começou a liberar detalhes do Raphael / AM5 que estavam mais ou menos em alinhamento com o que a GN recebeu um ano atrás.
Este slide pode ser interessante por outro motivo, ele lista um suposto codinome de Warhol , que se acredita ser uma atualização do Zen3 de algum tipo:
Detalhes do AMD Raphael de março de 2022, Fonte: Gamers Nexus
Há, no entanto, alguma disparidade entre as novas informações e o que parece ser uma apresentação interna de 2020. Para começar, o TDP das novas CPUs Raphael deve ir mais alto, até 120 W, enquanto os slides antigos listavam até 105W TDP. O que pode certamente ser interessante é que os slides da GamersNexus também listam notebooks para jogos da série Raphael , o que não foi especulado antes. No momento, acredita-se que o Raphael será oferecido junto com o Phoenix APU, que também contará com a arquitetura central do Zen4.
Os slides também confirmam um codinome para Zen4 CCD, que é Durango . De acordo com este slide de 2020, Raphael apresentaria o Zen4 CCD feito na tecnologia de processo TSMC N5 e CIOD3 no processo N7 da TSMC . O slide também reafirma rumores anteriores de que o Raphel apresentaria gráficos integrados no chip , que seriam baseados no Navi2 oferecendo 'desempenho gráfico de desktop de nível básico'.
Outro slide mostrando o pacote AM5 apresenta detalhes sobre a configuração CIOD3 e CCD duplo Durango. Como diz o slide, o CCD secundário é opcional. No entanto, ele não mostra uma configuração de CCD triplo (que havia rumores de outras fontes). Além disso, também sugere que cada CCD tem até 8 núcleos e 16 threads, o que é mais uma confirmação de que a configuração do núcleo do CCD não teria mudado em comparação com o CCD do Zen3.
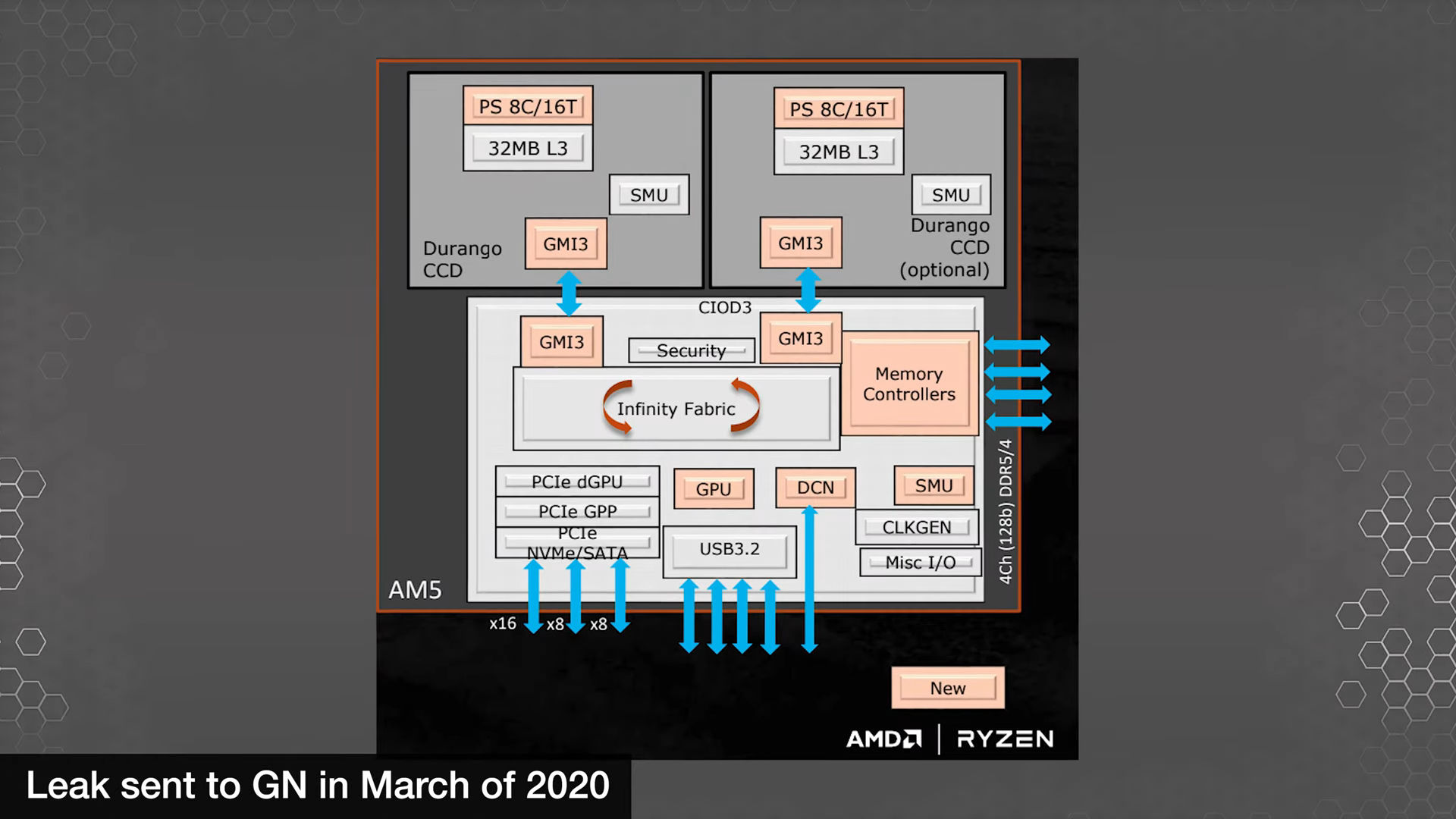
Detalhes do AMD AM5 de março de 2022, Fonte: Gamers Nexus
Outro slide mostra 'Raphael AM4 SOC'. Não está claro se isso se refere a um APU de baixa potência projetado com suporte a AM4 em mente (o que implicaria que o Raphel também poderia lançar para o soquete AM4 de alguma forma) ou simplesmente mostra informações incorretas ou desatualizadas. Independentemente desse fato, este slide também vai de encontro a um relatório recente de que o Raphel oferece suporte a até 28 pistas PCIe.
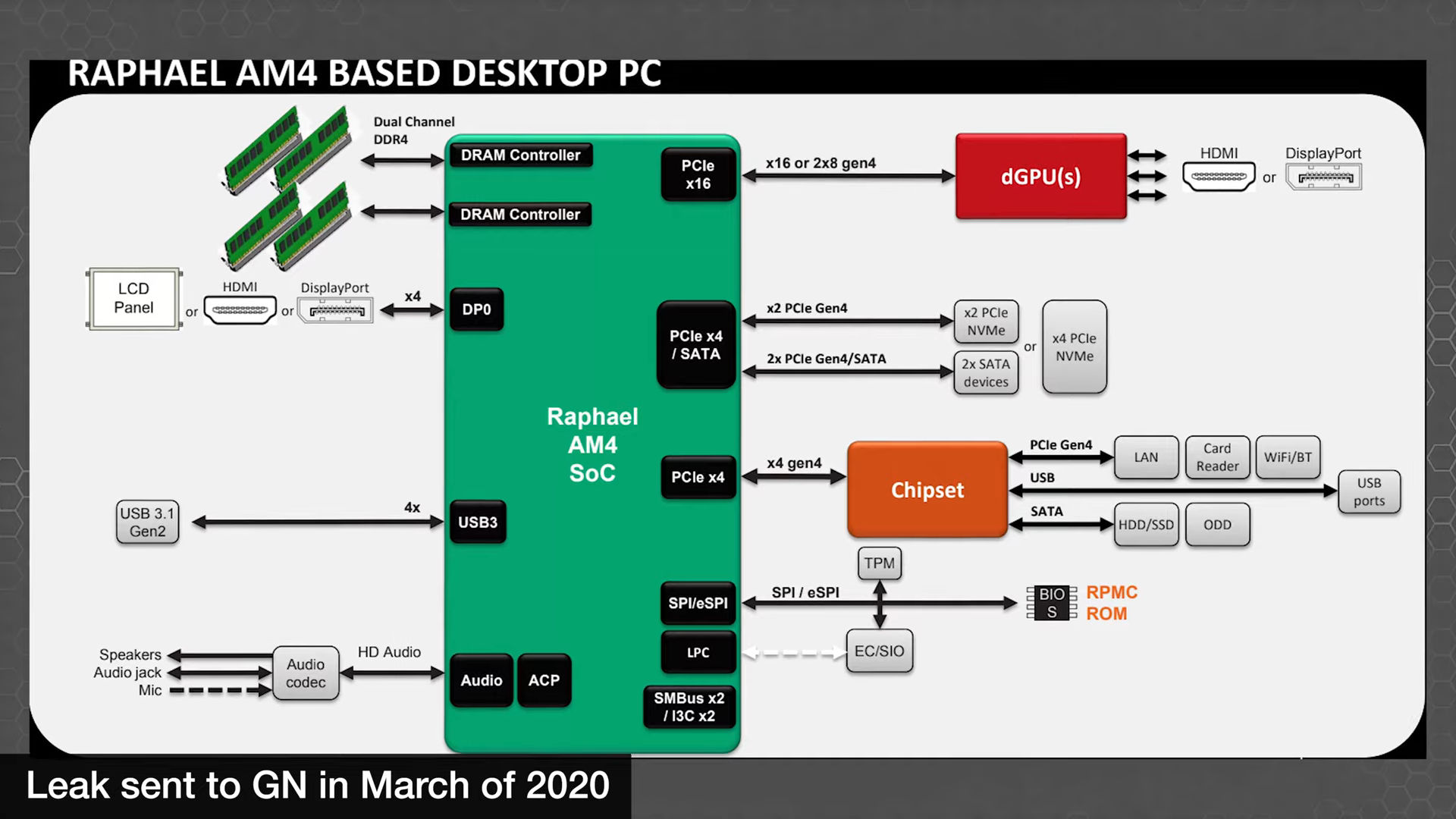
Informações do SoC AMD Raphael AM4 de março de 2022, Fonte: Gamers Nexus
Todos esses dados estão sendo comparados aos relatórios ExecutableFix recentes que revelaram o design do pacote AM5 (LGA1718) que está por vir e o dissipador de calor integrado do Raphael.
A ExecuFix deu um passo além e também revelou que Raphael suportaria apenas memória DDR5 (que novamente é ao contrário do slide acima listando apenas DDR4) e oferecerá TDP de até 170W (supostamente para um SKU de edição especial).
No momento, o AMD Raphel deve estrear no final de 2022. A AMD revelou na Computex que vai começar a produção de seus CPUs Zen3 baseados em V-Cache no início deste ano, o que sugere uma possível atualização do Zen3 no início de 2022. Isso pode servir como um interino atualize até que o Zen4 Raphael comece a funcionar.
AMD Embedded Roadmap for 2020-2023 lists Zen4 EPYC with 64+ cores - VideoCardz.com
AMD EPYC 7004 with 64+ cores We received a slide showing a (very) old roadmap featuring Zen4 embedded products. The roadmap is clearly dated, as it lists the already released Zen3 EPYC 7003 series as ‘concept’. It also lacks the Ryzen V2000 Embedded series, which were released last year with...
videocardz.com
O dissipador de calor da CPU AMD Raphael supostamente tem recortes abertos para capacitores
Atualização no design AMD Raphael IHS
ExecutableFix compartilhou uma nova renderização do futuro processador AMD Raphael baseado na arquitetura Zen4.
AMD Raphael CPU heatspreader allegedly has open cutouts for capacitors - VideoCardz.com
Update on AMD Raphael IHS design ExecutableFix has shared a new render of the upcoming AMD Raphael processor based on Zen4 architecture. AMD Raphael would have a much more sophisticated design than previously expected. Not only does the integrated heat spreader (IHS) for Raphael CPU does not...
videocardz.com
O AMD Raphael teria um design muito mais sofisticado do que o esperado anteriormente. Não apenas o dissipador de calor integrado (IHS) para Raphael CPU não tem um design uniforme, mas supostamente também tem aberturas para capacitores. Esta é uma grande atualização em relação ao design IHS simples das CPUs AM4 Ryzen.


ExecutableFix havia revelado anteriormente que o pacote AM5 exigirá um soquete Land Grid Array (LGA), que substituiria os pinos da CPU do Zen3 por almofadas. Alguns usuários notaram que não havia capacitores na parte de trás do processador e não havia muito espaço no outro lado. Assim, foi especulado que esses capacitores poderiam estar escondidos sob o IHS ou nos interruptores ao redor do IHS. Este último foi provado correto, pelo menos está de acordo com o último vazamento do ExecuFix:

Hoje cobrimos um vazamento diferente do AM5 da Gamers Nexus , que obteve acesso a supostos slides internos da AMD confirmando os codinomes de Raphael e Warhol. Os dados apresentados não eram tão precisos quanto os relatórios do ExectuFix, mas esses slides são desatualizados e claramente houve uma mudança desde que foram feitos.
O AMD Raphael deve estrear no final de 2022 com núcleos Zen4 no soquete AM5 (LGA1178). Espera-se que essas séries de CPU apresentem suporte DDR5 exclusivamente e só irão suportar o padrão PCIe Gen4 no lançamento. Parte disso pode mudar com o tempo, à medida que a plataforma AM5 se torna mais popular à medida que a AMD lança mais CPUs para este novo soquete.
O novo design do Raphael IHS será perinatalmente um pesadelo terrível, no entanto, ainda não foi confirmado se as novas CPUs Zen4 são soldadas ao IHS como acontece com as CPUs Ryzen topo de linha atualmente.
@RHBH @nando3d
Última edição:
Meio bizarro esse design aí, pq não encapar tudo? Será por problemas de dissipação de calor?
eu suspeito que vão mudar a base do cooler.
Incrível ver a evolução da AMD com a arquitetura Zen!
olha pra qualquer placa de vídeo acima da 3060 eu passaria longe da série 3000 do ryzen, um amigo meu tem um 3700x com uma rtx 3070 e em jogos competitivos é ridículo o quanto ele fica capado quando ultrapassa os 200 fps, ele joga fortnite, cs go e até pes, em todos ele faz muito menos fps do que deveria, a 3070 dele acaba rendendo uns 20 a 30% pior tipo no desempenho de uma rtx 2070 com um 5600x
Estou no mesmo dilema aqui, tenho um 3700x em uma X470 Gaming 7, RTX 2080 e 32GB 3600, estou esperando a poeira baixar um pouco pra pegar uma 3070TI, mas queria trocar meu CPU também por um 5800x, jogo em Quad HD, não sei se realmente vale a pena gastar quase 3k em um novo CPU.
Desde do início do ZEN 3 a AMD já planejava colocar o 3D V-Cache futuramente, seja no desktop ou nos servidores
Os TSV's nos ZEN 3 são a prova disso
No spoiler está a fonte original do comentário
Comentários interessantes estão em negritos, é sobre o 3D V-Cache
Veja os próprios slides da TSMC sobre a linha do tempo desse recurso (Chip on Wafer):

A qualificação só será feita até o quarto trimestre de 2021! Isso significa que a AMD usa esse recurso no segundo em que ele se torna disponível na fundição. E lembre-se, essa é a primeira fundição do mundo a fornecê-lo, já que a Intel só chegará à tecnologia 3D equivalente em 2023, ao que parece.
Portanto, a AMD conseguiu produzir em massa um CCD no quarto trimestre de 2020 com toneladas de TSVs incorporados para esse recurso, que só estará disponível um ano depois. E eles conseguiram fazer isso em segredo quase total (escondido à vista de todos)!
E eu pensei que o Zen3, embora uma atualização muito boa, parecia um pouco desanimador em comparação com as mudanças de paradigma do Zen 1 e Zen 2. Bem, não mais
 forums.anandtech.com
1) Já é difícil sem qualquer empilhamento 3D, para tornar L1 maior, mantendo a latência tão rápida. Está basicamente no caminho crítico para muitas coisas, 32kb ou 48kb L1D é o máximo que é possível atualmente para X86 com páginas de 4 KB e 4-5 ciclos de latência. Latência e uso de energia são o problema aqui, não na área.
forums.anandtech.com
1) Já é difícil sem qualquer empilhamento 3D, para tornar L1 maior, mantendo a latência tão rápida. Está basicamente no caminho crítico para muitas coisas, 32kb ou 48kb L1D é o máximo que é possível atualmente para X86 com páginas de 4 KB e 4-5 ciclos de latência. Latência e uso de energia são o problema aqui, não na área.
2) L2 é um ponto ideal de 10-15 ciclos de latência e tamanho, você pode aumentá-lo um pouco, mas em algum ponto a latência e o poder começam a aumentar e a verdadeira questão se torna - cada núcleo realmente precisa de um enorme L2 privado, ou talvez aqueles os transistores podem ser melhor usados como cache L3.
3) Chegamos então ao cache L3, que tem 40-50 ciclos de latência e é compartilhado. Ele não pode servir como L2, pois é muito lento e "compartilhado" significaria que o preço dos conflitos de endereço, etc., mataria o desempenho muito rápido.
Portanto, todas as 3 camadas são necessárias e apenas L2 e L3 podem se beneficiar do empilhamento 3D:
1) para L2, os benefícios são discutíveis, o empilhamento 3D adiciona alguma latência, o acesso rápido em cache grande aumenta o uso de energia. Em pouco tempo você chega a situações como a que a Intel teve com o Skylake - o produto básico tinha 256kb com 4-Way L2, que estava prejudicando muito o desempenho. Isso foi feito para que o produto de servidor pudesse ter 1 MB L2 com 16 vias. A ironia é que eles tiveram que conviver com essa decisão retardada por muito mais tempo do que planejaram")
. Duvido que a AMD repetisse esse erro, para transformar produtos sem pilhas 3D em algum pequeno L2 estúpido com decisões estruturais ruins.
2) L3 é onde está o Santo Graal do empilhamento 3D. Requisitos de latência razoáveis, arquitetura - fatias hash de endereço independentes de L3 - prontas para grande escala. Se alguém olhou o diagrama ZEN3, L1-> L2 é 32 + 32 bytes e L2-L3 também é 32 + 32 bytes. não há gargalo, portanto, o núcleo tem acesso à largura de banda total, desde que venha de L3. Pronto para escalar com o tamanho L3 em outras palavras
forums.anandtech.com
No design Zen atual, L2 é privado para o núcleo e inclui L1. L3 é vítima. Realmente não posso pular L2, as implicações disso são realmente enormes.
L1 / L2 estão envolvidos em operações MMU e paginação também. Ignorar L2 basicamente significa o minúsculo L1 envolvido no gerenciamento de um conjunto de trabalho de páginas razoavelmente grandes, não tenho certeza.
Além disso, L1 é basicamente parte do próprio núcleo. A planta baixa do núcleo inclui o L1, os TLBs, o cache uop e assim por diante. Como os outros elementos do núcleo e L1 estão rodando no mesmo clock, é importante manter a planta baixa para garantir a integridade do sinal, atraso de propagação, etc. para arquiteturas de alto clock como x86. Empilhar não é uma opção aqui, a menos que você não se importe em limitar a velocidade do clock. Ou alguém criou uma planta baixa em 3D totalmente radical.
O L3 com seu próprio domínio de clock (até a própria AMD mencionou que eles podem ser acionados por clock de forma independente) pode operar independente do núcleo.
Então eu suponho que mesmo nas várias encarnações do núcleo Zen (em dispositivos móveis, consoles, desktops, etc.) eles estão mexendo no L3, mas a planta baixa do núcleo permanece a mesma.
forums.anandtech.com
Esta é a página anandtech com o empilhamento 3D 2.5D nd que a TSMC tem trabalhado. Eu vinculei isso várias vezes aqui já que eu esperava que fosse usado para o Zen4. Eu acho que isso deveria ter sido especulado pelo Zen3.

 www.anandtech.com
www.anandtech.com
A tecnologia para o chip de cache é provavelmente TSMC-SoIC, que tem uma condutividade térmica muito boa. Ian acabou de fazer um artigo sobre isso:
 www.anandtech.com
forums.anandtech.com
Eles continuam a jogar toneladas de cache nele por três coisas:
www.anandtech.com
forums.anandtech.com
Eles continuam a jogar toneladas de cache nele por três coisas:
1) É um lugar onde podem mostrar uma vantagem competitiva. Eles podem ter "mais" cache do que seu concorrente, obtendo, assim, uma vantagem de marketing. Porém, isso é basicamente apenas acadêmico.
2) A AMD ainda tem um pequeno déficit de latência e desempenho de memória em comparação aos produtos Intel em segmentos de mercado concorrentes. Jogar o cache L3 extra no problema significa que mais e mais acessos à memória param no cache e são capazes de demonstrar latência mais baixa e maior rendimento, em média, do que o produto de seus concorrentes.
3) há um argumento a ser feito que economizará energia do package. Os acessos à memória que não precisam atingir o IOD ou o barramento de memória principal consumirão menos energia do que aqueles que precisam. Se você economizar energia lá, pode gastá-la em outras partes do chip, como o CCD, ou simplesmente não gastar.
forums.anandtech.com
Ian também confirmou na mesma postagem que é um único die (mais denso), não 2 stacks. Embora o BIOS do servidor AMD mostre claramente que os cpus do servidor terão até 4 stacks, habilitáveis em configurações de 1, 2 e 4 stacks no BIOS:
Mais alguns detalhes e como a AMD planejou isso também podem ser encontrados aqui
Bem, acho que não é nem mesmo um boato. Está literalmente lá nas BIOS.
forums.anandtech.com
forums.anandtech.com
Uma fonte cita que a AMD afirma que eles tiveram que fazer as matrizes CCD mais finas para acomodar o cache empilhado sob o dissipador AM4. Isso poderia explicar a nova revisão.
forums.anandtech.com
Portanto, a AMD anunciou o empilhamento 3D de SRAM em sua Computex Keynote. Eu estou supondo que com um monte de LLCs, eles podem implementar esse cache micro-op virtualizado de forma viável. A melhor parte é que é essencialmente HBM SRAM, portanto, não só a taxa de acertos e a capacidade são aprimoradas, como a largura de banda também é muito maior. Chiplets SRAM separados podem ser fabricados em wafers separados, que devem ser fáceis de produzir, pois as matrizes são pequenas e os rendimentos para SRAM são muito bons. Esta tecnologia vale por si só um IPC de dois dígitos.
forums.anandtech.com
Em projetos futuros da arquitetura Zen, todo o L3 $ pode estar em um die vertical empilhado, liberando mais espaço para núcleos maiores (incluindo L1 $ e L2 $) ou para adicionar mais núcleos.
forums.anandtech.com
O cache não é onde esquenta o calor. Mesmo em tarefas pesadas de BW como Linpack etc, os principais infratores são unidades de FPU vetor. E devido à forma como a "segmentação" do cache L3 funciona, o calor se espalha ainda mais, já que o hash tem 3x mais fatias para trabalhar.
Há uma razão pela qual a AMD não está cobrindo L2 e núcleos e aderindo exatamente à área L3 existente, eles planejaram isso desde o início do ZEN3.
Lembra-se do lendário vazamento inicial do ZEN3, que dizia sobre o tamanho do 8C CCX e todas as outras coisas que encontramos eram 100% verdadeiras? Naquela mesma apresentação havia também uma joia de ouro de "32 + MB L3", na época pensávamos que fosse para coisas de "servidor", aumentar para 48 ou mais, mas estava aqui o tempo todo, destinado a empilhar aqueles 32 MB L3 .
Então, sim, eles tiveram as vias e a infraestrutura necessária em todos os chips ZEN3 desde o primeiro dia.
forums.anandtech.com
forums.anandtech.com
Acho que eles estão sendo tímidos quanto aos prazos porque não querem diminuir suas vendas atuais. Por que alguém em sã consciência compraria um 5900x agora sabendo que 15% mais rápido com 2x o cache está a apenas alguns meses de distância? Além disso, o fato de zen 3 ter sido projetado com cache empilhado em mente desde o início diz muito sobre o quão longe eles estão em seu desenvolvimento. No momento, é a melhor jogada deles para levar as coisas devagar e tenho certeza que ouviremos mais quanto mais perto estivermos do lançamento de Alderlakes. Também id presumir que seu principal uso para os chips de cache seja a fronteira. Há um motivo pelo qual eles estão demonstrando essa tecnologia primeiro em chips de desktop, embora pareça que seu melhor uso seja em gráficos e datacenter; Aposto que isso se deve em parte aos NDAs.
forums.anandtech.com
Se o "6700G" obtiver isso com 12-16 UCs, o jogo para a coroa iGPU termina. Será 2-2,5x mais rápido do que o que está disponível agora.
forums.anandtech.com
Rembrandt será 2x mais rápido sem o V-Cache
forums.anandtech.com
Aurora deveria estar pronto antes, foi ganho pela Intel e está sendo construído com chips Sapphire Rapid que têm chips PCIe 5.0, "Rambo cache", HMB2 no pacote se necessário (e parece um software de espaço de memória unificado semelhante). O problema é que ele está usando micro-bumps para empilhamento (bem, também é muito tarde, mas isso não era certo quando o Frontier foi anunciado). Então, se alguma coisa, a Intel teve a vantagem de I / O.
Tinha que haver algum ingrediente secreto nas ofertas da AMD para ganhar o Frontier como eles fizeram. Este é certamente um diferenciador chave. Tenha em mente que a solução V-cache provavelmente tem duas camadas(já que fica em cima de 32 MB L3 e é exatamente tão grande no mesmo processo). Não há nada que impeça a AMD de adicionar mais camadas para algumas CPUs de servidor e estou convencido agora que o CDNA2 também tem esse empilhamento.
E embora tudo isso só seja possível por causa das proezas de engenharia da AMD, tenha em mente que essa também é a vitória da TSMC tanto quanto da AMD. Eles são a única fundição que tem algo parecido pronto neste período de tempo. Os obstáculos que a TSMC teve que percorrer para fazer este trabalho (e ser produtível em escala) também são enormes.
Em suma, desde o Zen 2, parece que é a trifeta da execução (Sinopse + AMD + TSMC) que está de parabéns. A AMD não poderia simplesmente fazer isso sozinha.
forums.anandtech.com
Muito estranho. Eu esperava que eles usassem caches empilhados de algum tipo por um bom tempo, mas achei que era um design Zen 4. Eu estava especulando que isso permitiria que eles fizessem algumas versões de cache muito grandes para aplicativos de banco de dados e HPC de ponta. Também pode permitir o uso de um processo especializado ou um processo mais antigo para fazer os caches com eficiência. Antes de Roma, a Intel ainda tinha algumas vantagens com um cache L3 monolítico de 38,5 MB. O cache de 32 MB no Zen 3 percorreu um longo caminho. Indo para 32 L3 + 64 L4 ou 96 L3 (não tenho certeza de como isso está organizado) realmente torna todos os Xeons low-end.
Isso aparentemente foi demonstrado no Zen 3. Eu me pergunto se o Zen 3 original tinha conectividade para o chip de cache empilhado ou se foi adicionado recentemente na nova revisão. Eles quase certamente tiveram que adicionar alguns elementos de design ao Zen 3 desde o início. O design é um pouco estranho com o silício estrutural cobrindo os núcleos da CPU, já que o chip de cache empilhado só parece cobrir o L3 de 32 MB existente. A condutividade térmica do silício não seria tão boa, mas pode não importar. Parece que isso pode usar a tecnologia da TSMC que permite o empilhamento de chips sem esferas de micro-solda entre eles. Eu esqueci como é chamado.
Há um artigo da Anandtech sobre as diferentes tecnologias de empilhamento 2.5D e 3D da TSMC. A parte superior (na verdade, inferior devido ao flip-chip) precisaria ser afinada para expor as vias de silício, portanto, a condutividade térmica pode não ser um grande problema devido à proximidade das camadas do transistor da superfície. Eles provavelmente precisam usar silício estrutural para fornecer as mesmas características de expansão térmica.
Se as imagens nos slides forem precisas, gostaria de saber se haverá um chip de cache de cobertura total com capacidade de 128 MB para aplicativos de ponta.
forums.anandtech.com
Não vejo razão para não empilhar chips feitos em processos diferentes. Tudo o que você precisa para alinhar são os TSVs, cuja localização é independente do processo. Os TSVs se conectam às camadas de metal e não se importam com a localização ou densidade dos transistores (exceto por não colocá-los onde um TSV possa penetrar em chips projetados para empilhar mais de dois níveis de altura).
forums.anandtech.com
Este é um artigo mais antigo:
 www.anandtech.com
www.anandtech.com
Ele lista diferentes pitches de TSV, mas também diz que eles podem ser capazes de baixá-lo para 0,9 mícrons de 9 mícrons em 7 nm e 6 mícrons para 5 nm. Isso tem quase um ano de idade, então eles podem ter um tom significativamente menor agora. Não vejo por que eles não seriam capazes de misturar o die de 7 e 5 nm; eles só precisam usar um passo de tsv compatível. O die de cache de 7 nm é presumivelmente um processo diferente, presumivelmente de uma linha diferente. Misturar algo feito em um local de fábrica diferente pode ser difícil, então isso pode ser uma limitação. O die do cache é provavelmente um pouco mais barato de produzir. Duvido que ele precise de tantas camadas de metal quanto a matriz de CPU completa, portanto, menos processamento. Se obtivermos uma versão de 5 nm dele com o Zen 4, então pode ser uma quantidade ainda maior de cache.
Este é um passo muito menor do que as soluções de esferas de micro-solda, então a tecnologia TSMC está habilitando isso para a AMD. 9 mícrons ainda são 9000 nm, então isso não é exatamente o mesmo que estar no mesmo die, mas está mais próximo do que qualquer outra coisa.
forums.anandtech.com
Sim, o roteiro do TSMC mostra apenas empilhamento de COW 7nm em 7nm e 5nm em 5nm lançado mais tarde. Seria mais difícil empilhar matrizes de nós diferentes em um passo tão fino, nós diferentes deveriam ter padrões de camadas compatíveis ou, pelo menos, bibliotecas compatíveis com nós totalmente construídas. Até agora, os roteiros da TSMC não mostram que isso está planejado, eles mostram apenas o cow-stacking do mesmo nó.
forums.anandtech.com
Dito isso, a TSMC tem um plano de construção substancial para montagem e teste de SoIC. Observe também que a TSMC considera o N6 como parte da geração N7 no que diz respeito ao empilhamento SoIC, e que seu roteiro tem empilhamento N3 sobre N5 para o final de 2023.
forums.anandtech.com
O fato de haver um zen 3 bios mostrando até 4 stacks altas parece indicar que teremos 4 stacks em "milan-x". No entanto, o Desktop Ryzen está provavelmente limitado a 1 stack alta. Para o Zen 4, podemos realmente obter núcleos empilhados em um intermediário. A potência da cpu de 5 velocidades pci-express para as interconexões do molde de I/O será alta, portanto, colocá-los empilhados em um intermediário reduzirá a potência significativamente. É muito difícil especular quando o empilhamento de chips entra em jogo, uma vez que existem tantas possibilidades.
forums.anandtech.com
Observe como com o Zen 3 a AMD unificou o L3 $, finalmente tornando todos os 32 MB acessíveis para todos os núcleos. Acontece que isso não parou por aí, mas foi planejado para ser escalável bem além disso, 96 MB como demo, 288 MB como assumido para 4 stacks.
L2 $ está em uma posição completamente diferente, sendo privado para cada núcleo. Com L3 $ todos os TSVs somam uma vantagem para cada núcleo, com L2 $ um precisaria de TSVs massivos apenas para o benefício de um único núcleo cada.
Tenho certeza de que haverá maneiras inovadoras de expandir a usabilidade do L2 $. Mas aumentar seu tamanho por meio do empilhamento parece muito improvável para mim.
Com cada grande geração Zen, a AMD encontrou uma maneira de dimensionar algo de forma massiva.
Parece que foi nisso que a AMD trabalhou para o Zen 3, que permitiria 288 MB L3 $ por CCX, somando 2304 MB em um chip Epyc de 64 núcleos.
forums.anandtech.com
Se você olhar apenas para a SRAM, é apenas uma parte do espaço real, talvez eles reutilizem o mesmo controle e tags L3.
Eu suspeito que a parte superior da SRAM se espalhou pelo cache L2 de cada núcleo também.
De acordo com Andreas Schilling no Twitter que falou com a AMD.
- O Zen 3 foi feito com isso em mente. Nenhuma modificação necessária.
- é 1 stack de 64 MB de cache
- Na verdade, aumenta o cache de nível 3. Com aumento mínimo de latência.
Baseado nisso e na imagem acima eu suspeito que 64 MB é bem mais denso do que 32 MB abaixo. Suspeito que o controle L3 e as tags L3 também suportam a SRAM no V Cache.


 www.techpowerup.com
www.techpowerup.com
E o socket também
Os TSV's nos ZEN 3 são a prova disso
No spoiler está a fonte original do comentário
Comentários interessantes estão em negritos, é sobre o 3D V-Cache
Veja os próprios slides da TSMC sobre a linha do tempo desse recurso (Chip on Wafer):
A qualificação só será feita até o quarto trimestre de 2021! Isso significa que a AMD usa esse recurso no segundo em que ele se torna disponível na fundição. E lembre-se, essa é a primeira fundição do mundo a fornecê-lo, já que a Intel só chegará à tecnologia 3D equivalente em 2023, ao que parece.
Portanto, a AMD conseguiu produzir em massa um CCD no quarto trimestre de 2020 com toneladas de TSVs incorporados para esse recurso, que só estará disponível um ano depois. E eles conseguiram fazer isso em segredo quase total (escondido à vista de todos)!
E eu pensei que o Zen3, embora uma atualização muito boa, parecia um pouco desanimador em comparação com as mudanças de paradigma do Zen 1 e Zen 2. Bem, não mais
Page 60 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 60 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
2) L2 é um ponto ideal de 10-15 ciclos de latência e tamanho, você pode aumentá-lo um pouco, mas em algum ponto a latência e o poder começam a aumentar e a verdadeira questão se torna - cada núcleo realmente precisa de um enorme L2 privado, ou talvez aqueles os transistores podem ser melhor usados como cache L3.
3) Chegamos então ao cache L3, que tem 40-50 ciclos de latência e é compartilhado. Ele não pode servir como L2, pois é muito lento e "compartilhado" significaria que o preço dos conflitos de endereço, etc., mataria o desempenho muito rápido.
Portanto, todas as 3 camadas são necessárias e apenas L2 e L3 podem se beneficiar do empilhamento 3D:
1) para L2, os benefícios são discutíveis, o empilhamento 3D adiciona alguma latência, o acesso rápido em cache grande aumenta o uso de energia. Em pouco tempo você chega a situações como a que a Intel teve com o Skylake - o produto básico tinha 256kb com 4-Way L2, que estava prejudicando muito o desempenho. Isso foi feito para que o produto de servidor pudesse ter 1 MB L2 com 16 vias. A ironia é que eles tiveram que conviver com essa decisão retardada por muito mais tempo do que planejaram
. Duvido que a AMD repetisse esse erro, para transformar produtos sem pilhas 3D em algum pequeno L2 estúpido com decisões estruturais ruins.
2) L3 é onde está o Santo Graal do empilhamento 3D. Requisitos de latência razoáveis, arquitetura - fatias hash de endereço independentes de L3 - prontas para grande escala. Se alguém olhou o diagrama ZEN3, L1-> L2 é 32 + 32 bytes e L2-L3 também é 32 + 32 bytes. não há gargalo, portanto, o núcleo tem acesso à largura de banda total, desde que venha de L3. Pronto para escalar com o tamanho L3 em outras palavras
Page 59 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 59 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
L1 / L2 estão envolvidos em operações MMU e paginação também. Ignorar L2 basicamente significa o minúsculo L1 envolvido no gerenciamento de um conjunto de trabalho de páginas razoavelmente grandes, não tenho certeza.
Além disso, L1 é basicamente parte do próprio núcleo. A planta baixa do núcleo inclui o L1, os TLBs, o cache uop e assim por diante. Como os outros elementos do núcleo e L1 estão rodando no mesmo clock, é importante manter a planta baixa para garantir a integridade do sinal, atraso de propagação, etc. para arquiteturas de alto clock como x86. Empilhar não é uma opção aqui, a menos que você não se importe em limitar a velocidade do clock. Ou alguém criou uma planta baixa em 3D totalmente radical.
O L3 com seu próprio domínio de clock (até a própria AMD mencionou que eles podem ser acionados por clock de forma independente) pode operar independente do núcleo.
Então eu suponho que mesmo nas várias encarnações do núcleo Zen (em dispositivos móveis, consoles, desktops, etc.) eles estão mexendo no L3, mas a planta baixa do núcleo permanece a mesma.
Page 58 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 58 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
3DFabric: The Home for TSMC’s 2.5D and 3D Stacking Roadmap
A tecnologia para o chip de cache é provavelmente TSMC-SoIC, que tem uma condutividade térmica muito boa. Ian acabou de fazer um artigo sobre isso:
AMD Demonstrates Stacked 3D V-Cache Technology: 192 MB at 2 TB/sec
Page 56 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 56 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
1) É um lugar onde podem mostrar uma vantagem competitiva. Eles podem ter "mais" cache do que seu concorrente, obtendo, assim, uma vantagem de marketing. Porém, isso é basicamente apenas acadêmico.
2) A AMD ainda tem um pequeno déficit de latência e desempenho de memória em comparação aos produtos Intel em segmentos de mercado concorrentes. Jogar o cache L3 extra no problema significa que mais e mais acessos à memória param no cache e são capazes de demonstrar latência mais baixa e maior rendimento, em média, do que o produto de seus concorrentes.
3) há um argumento a ser feito que economizará energia do package. Os acessos à memória que não precisam atingir o IOD ou o barramento de memória principal consumirão menos energia do que aqueles que precisam. Se você economizar energia lá, pode gastá-la em outras partes do chip, como o CCD, ou simplesmente não gastar.
Page 56 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 56 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Mais alguns detalhes e como a AMD planejou isso também podem ser encontrados aqui
Bem, acho que não é nem mesmo um boato. Está literalmente lá nas BIOS.
Page 56 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 56 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 57 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 57 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 53 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 53 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 58 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 58 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Há uma razão pela qual a AMD não está cobrindo L2 e núcleos e aderindo exatamente à área L3 existente, eles planejaram isso desde o início do ZEN3.
Lembra-se do lendário vazamento inicial do ZEN3, que dizia sobre o tamanho do 8C CCX e todas as outras coisas que encontramos eram 100% verdadeiras? Naquela mesma apresentação havia também uma joia de ouro de "32 + MB L3", na época pensávamos que fosse para coisas de "servidor", aumentar para 48 ou mais, mas estava aqui o tempo todo, destinado a empilhar aqueles 32 MB L3 .
Então, sim, eles tiveram as vias e a infraestrutura necessária em todos os chips ZEN3 desde o primeiro dia.
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
- Zen 1: Die Competitive Zeppelin. Oh, você pode usar 4 deles como 32 núcleos Epyc.
- Zen 2: chips e IOD separados. Oh, você pode usar 8 deles como 64 núcleos Epyc.
- Zen 3: Uh, algumas boas melhorias no IPC. Espere, 32 MB SRAM empilhado também, infiltrado como cache de jogo v2 em uma palestra da Computex. Você pode usar 8 deles para um total de 288 MB L3 por CCD, para um total de 2304 MB L3 em um Epyc de 64 núcleos ?
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 55 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 55 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Tinha que haver algum ingrediente secreto nas ofertas da AMD para ganhar o Frontier como eles fizeram. Este é certamente um diferenciador chave. Tenha em mente que a solução V-cache provavelmente tem duas camadas(já que fica em cima de 32 MB L3 e é exatamente tão grande no mesmo processo). Não há nada que impeça a AMD de adicionar mais camadas para algumas CPUs de servidor e estou convencido agora que o CDNA2 também tem esse empilhamento.
E embora tudo isso só seja possível por causa das proezas de engenharia da AMD, tenha em mente que essa também é a vitória da TSMC tanto quanto da AMD. Eles são a única fundição que tem algo parecido pronto neste período de tempo. Os obstáculos que a TSMC teve que percorrer para fazer este trabalho (e ser produtível em escala) também são enormes.
Em suma, desde o Zen 2, parece que é a trifeta da execução (Sinopse + AMD + TSMC) que está de parabéns. A AMD não poderia simplesmente fazer isso sozinha.
Page 54 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 54 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Isso aparentemente foi demonstrado no Zen 3. Eu me pergunto se o Zen 3 original tinha conectividade para o chip de cache empilhado ou se foi adicionado recentemente na nova revisão. Eles quase certamente tiveram que adicionar alguns elementos de design ao Zen 3 desde o início. O design é um pouco estranho com o silício estrutural cobrindo os núcleos da CPU, já que o chip de cache empilhado só parece cobrir o L3 de 32 MB existente. A condutividade térmica do silício não seria tão boa, mas pode não importar. Parece que isso pode usar a tecnologia da TSMC que permite o empilhamento de chips sem esferas de micro-solda entre eles. Eu esqueci como é chamado.
Há um artigo da Anandtech sobre as diferentes tecnologias de empilhamento 2.5D e 3D da TSMC. A parte superior (na verdade, inferior devido ao flip-chip) precisaria ser afinada para expor as vias de silício, portanto, a condutividade térmica pode não ser um grande problema devido à proximidade das camadas do transistor da superfície. Eles provavelmente precisam usar silício estrutural para fornecer as mesmas características de expansão térmica.
Se as imagens nos slides forem precisas, gostaria de saber se haverá um chip de cache de cobertura total com capacidade de 128 MB para aplicativos de ponta.
Page 54 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 54 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 60 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 60 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
TSMC Teases 12-High 3D Stacked Silicon: SoIC Goes Extreme
Ele lista diferentes pitches de TSV, mas também diz que eles podem ser capazes de baixá-lo para 0,9 mícrons de 9 mícrons em 7 nm e 6 mícrons para 5 nm. Isso tem quase um ano de idade, então eles podem ter um tom significativamente menor agora. Não vejo por que eles não seriam capazes de misturar o die de 7 e 5 nm; eles só precisam usar um passo de tsv compatível. O die de cache de 7 nm é presumivelmente um processo diferente, presumivelmente de uma linha diferente. Misturar algo feito em um local de fábrica diferente pode ser difícil, então isso pode ser uma limitação. O die do cache é provavelmente um pouco mais barato de produzir. Duvido que ele precise de tantas camadas de metal quanto a matriz de CPU completa, portanto, menos processamento. Se obtivermos uma versão de 5 nm dele com o Zen 4, então pode ser uma quantidade ainda maior de cache.
Este é um passo muito menor do que as soluções de esferas de micro-solda, então a tecnologia TSMC está habilitando isso para a AMD. 9 mícrons ainda são 9000 nm, então isso não é exatamente o mesmo que estar no mesmo die, mas está mais próximo do que qualquer outra coisa.
Page 61 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 61 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 60 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 60 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 61 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 61 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Page 60 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 60 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
L2 $ está em uma posição completamente diferente, sendo privado para cada núcleo. Com L3 $ todos os TSVs somam uma vantagem para cada núcleo, com L2 $ um precisaria de TSVs massivos apenas para o benefício de um único núcleo cada.
Tenho certeza de que haverá maneiras inovadoras de expandir a usabilidade do L2 $. Mas aumentar seu tamanho por meio do empilhamento parece muito improvável para mim.
Com cada grande geração Zen, a AMD encontrou uma maneira de dimensionar algo de forma massiva.
Parece que foi nisso que a AMD trabalhou para o Zen 3, que permitiria 288 MB L3 $ por CCX, somando 2304 MB em um chip Epyc de 64 núcleos.
Page 60 - Discussion - Speculation: Zen 4 (EPYC 4 "Genoa", Ryzen 7000, etc.)
Page 60 - Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.
Eu suspeito que a parte superior da SRAM se espalhou pelo cache L2 de cada núcleo também.
De acordo com Andreas Schilling no Twitter que falou com a AMD.
- O Zen 3 foi feito com isso em mente. Nenhuma modificação necessária.
- é 1 stack de 64 MB de cache
- Na verdade, aumenta o cache de nível 3. Com aumento mínimo de latência.
Baseado nisso e na imagem acima eu suspeito que 64 MB é bem mais denso do que 32 MB abaixo. Suspeito que o controle L3 e as tags L3 também suportam a SRAM no V Cache.
AMD "Zen 3+" Microarchitecture is "Zen 3" with 3D Vertical Cache Technology, 15% Gaming Perf Gain
I'm in the camp hoping for an AM4 6000 series mini-refresh; was planning to buy a 5900X or 5950X, but I can wait for a 6900X or 6950X. It would also be the best send-off for AM4 if AMD could squeeze out one final ;P at Intel as well.
--- Post duplo é unido automaticamente: ---
Meio bizarro esse design aí, pq não encapar tudo? Será por problemas de dissipação de calor?
eu suspeito que vão mudar a base do cooler.
E o socket também
Última edição:
Users who are viewing this thread
Total: 2 (membros: 0, visitantes: 2)