Massa também curtir.PCB vermelho voltando as raízes!
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
[TÓPICO DEDICADO] NAVI - próxima geração de GPUs da AMD
- Iniciador de Tópicos brender
- Data de Início
Damn esse design tá bonito pra caralho e os 2x8 Pin praticamente confirma que a Placa só vai até 375W.A placa de vídeo AMD Radeon RX 7900 foi fotografada, dois conectores de alimentação de 8 pinos confirmados.
As fotos foram postadas por @9550pro que afirma tê-las de um grupo de bate-papo QQ fechado.
A placa é claramente um protótipo, com design de placa vermelha e pontos de contato de tensão em alguns lugares. O que está claro, porém, é que este design combina com o que a AMD vem provocando no final de agosto com três listras vermelhas no dissipador de calor.

A placa é mais longa que o design da Radeon 6900, mas apresenta a mesma configuração de conector de alimentação que a GPU RDNA2, que é um design de conector duplo de 8 pinos. O cooler não parece ter espaço para conectores de alimentação adicionais, então este pode ser o Radeon 7900 XT ou o carro-chefe 7900 XTX, que provavelmente compartilharão o mesmo design de três ventoinhas.

Este protótipo não é um produto final, o que claramente está faltando é a placa traseira que está presente em todos os modelos de referência RDNA2 de ponta. Além disso, não se preocupe com o PCB vermelho, ele será alterado para preto com certeza.
A AMD agora está pronta para anunciar sua série Radeon 7900 nesta quinta-feira, com rumores de que o lançamento do produto será no início de dezembro. Pelo menos duas placas devem ser anunciadas, incluindo 7900XT e 7900XTX baseadas na GPU Navi 31 com arquitetura RDNA3 e design inovador de chiplet.

Fonte: @9550pro
Não sendo um monstro de tamanho, consumindo menos e tendo 2x8 pinos já ceifa mais que a metade a 4090.
Isso daí é bem tranquilo pra RDNA 3Não sendo um monstro de tamanho, consumindo menos e tendo 2x8 pinos já ceifa mais que a metade a 4090.
É a maior mudança de Arquitetura da AMD desde Vega->RDNA só que dessa vez RT vem junto.
Tomara msm. Eu não ligo pra RT, mas sei que essa porra é aquele tipo de recurso que "vende". Então se conseguirem melhorar ele a nível acima das 3090 já estará de bom tamanho.Isso daí é bem tranquilo pra RDNA 3
É a maior mudança de Arquitetura da AMD desde Vega->RDNA só que dessa vez RT vem junto.
Outra coisa, falta dedicar recursos e foco pro time de software e criarem drivers decentes a partir de agora.
Drivers já estão num estado descente tem tempos Tho, agora com OpenGL e DX11 arrumados ta de boa.Tomara msm. Eu não ligo pra RT, mas sei que essa porra é aquele tipo de recurso que "vende". Então se conseguirem melhorar ele a nível acima das 3090 já estará de bom tamanho.
Outra coisa, falta dedicar recursos e foco pro time de software e criarem drivers decentes a partir de agora.
RT deve melhorar bastante porque RDNA 3 dobra a quantidade de ALUs por CU.
Te mandar a real que eu nunca tive problemas com drivers (e quando tive foi pq fiz over nas memórias e não estavam estáveis), mas me parece que ainda há mta sujeira para se limpar naquele monte de linha de código. Acho que só dps que as GCN pararem por completo o suporte que poderemos ver um salto a mais. Até pq ainda temos as Vega nas APUs recentes.
Mas tudo isso tmb pode ser um chute meu, não duvido.
Mas tudo isso tmb pode ser um chute meu, não duvido.
Concordaria contigo senão fosse o Fato de que RDNA foi um dos lançamentos mais problemáticos da AMD(Internamente a Placa tomou delay de 1 ano)... só com RDNA 2 que arrumaram mesmo os Drivers.Te mandar a real que eu nunca tive problemas com drivers (e quando tive foi pq fiz over nas memórias e não estavam estáveis), mas me parece que ainda há mta sujeira para se limpar naquele monte de linha de código. Acho que só dps que as GCN pararem por completo o suporte que poderemos ver um salto a mais. Até pq ainda temos as Vega nas APUs recentes.
Mas tudo isso tmb pode ser um chute meu, não duvido.
Sim agora estou curioso pra saber o desempenho dela!Damn esse design tá bonito pra caralho e os 2x8 Pin praticamente confirma que a Placa só vai até 375W.
Thread juntando todas as informações sabidas acerca das Radeon 7000 (RDNA3):
Resumo do resumo:
- Mudanças no WGP. Cada CU agora faz dupla-entrada FP32 (2xSPs);
- Navi31 e Navi32 aumentam o VRF para 192KB, enquanto o Navi33 e o Phoenix ainda têm 128 KB;
- RDNA3 usará apenas o motor geométrico NGG, ou seja, não será compatível com códigos GFX9 (acaba-se código legado das Polaris/Vega);
- Suporte à WMMA (Wave Matrix Multiply-Accumulate), com aceleração de INT8, FP16 e BF16. O MFMA (Matrix Fused Multiply-Add) do CDNA não está presente;
- Display Port 2.1, suporte à UHBR13.5, UHBR20 e Encode de AV1;
- Novas instruções para agilizar RTRT, inclusive algumas que poderão ser RT-Traversal (BVH). Mais informações aqui;
- InfCache com menor latência/maior largura de banda, muito mais flexível e agora endereçável para os desenvolvedores (mais informações aqui);
- Dobro de cache L0/L1, SW Instruction scoreboard, Ray Arbiter (não se sabe o que ambos fazem);
- Por fim, OREO (Opaque Random Export Order). Mais informações aqui (https://www.angstronomics.com/i/68134041/oreo).
O problema é que é difícil saber o quanto essas mudanças vão ajudar nos jogos. A 4090 mesmo tem mais que 2X as specs da 3090Ti em muitas coisas mas o ganho médio em vários jogos ficou na casa dos ~65% dependendo do review. Nem em jogos RT que a Nvidia fez mudanças mais bruscas teve 2X de ganho na média.
Essa lista para mim indica uma preocupação com a utilização melhor do hardware então veremos se a AMD vai conseguir um scalling melhor que a Nvidia.
Como a AMD possui uma GPU com RT mais fraco eu espero que pelo menos nos jogos com RT os ganhos sejam bem mais que 2X com o ideal sendo >3X.

Está esquecendo Clocks amigo, pode colocar quase 1ghz a mais do que RDNA 2, a maioria da performance da 4090 vem dos Clocks em Si.O problema é que é difícil saber o quanto essas mudanças vão ajudar nos jogos. A 4090 mesmo tem mais que 2X as specs da 3090Ti em muitas coisas mas o ganho médio em vários jogos ficou na casa dos ~65% dependendo do review. Nem em jogos RT que a Nvidia fez mudanças mais bruscas teve 2X de ganho na média.
Essa lista para mim indica uma preocupação com a utilização melhor do hardware então veremos se a AMD vai conseguir um scalling melhor que a Nvidia.
Como a AMD possui uma GPU com RT mais fraco eu espero que pelo menos nos jogos com RT os ganhos sejam bem mais que 2X com o ideal sendo >3X.
Damn esse design tá bonito pra caralho e os 2x8 Pin praticamente confirma que a Placa só vai até 375W.
Calma... essa é a referencia/founders.
Ainda vai ter a versão da Sapphire, atualmente as 6900/6950 Nitro e Toxic já usam 3 conectores...
Então pô referencia é 2x8, AIBs obviamente podem ir 3x8 principalmente PowerColor e Sapphire, XFX tho deve ficar no 2x8 mesmo.Calma... essa é a referencia/founders.
Ainda vai ter a versão da Sapphire, atualmente as 6900/6950 Nitro e Toxic já usam 3 conectores...
Que horas será o evento no horário BR ?
Agora que passou as eleições, a vida volta ao normal até o PT aprontar novo escambau no país, aproveitar as VGAs enquanto é possível.
Agora que passou as eleições, a vida volta ao normal até o PT aprontar novo escambau no país, aproveitar as VGAs enquanto é possível.
Uhum, posso sim :3Se não for pedir muito @dayllann , poderia fazer uma breve explicação do que é cada coisa ai em cima para um reles mortal como eu?

1) Mudanças no WGP: Cada CU agora faz dupla-entrada FP32 (2xSPs);
- O WGP (Processador de grupo de Trabalho) unia dois CU (Unidades Computacionais) e agora ele foi dobrado novamente, mas não existe mais como essa divisão, não existe mais CU, é apenas WGP (como o item 3 diz, todas as dependências/arquitetura legado da GFX9 foram deixadas para trás). Agora cada grupo de trabalho é composto por 256 Stream Processors (ALUs/FP32) que compartilham um só LDS e caches (instrução de shaders e de dados escalares). Na prática, somado ao Paralelismo a nível de instrução, vai permitir uma maior vazão de dados, agilizando seu processamento.
2) Navi31 e Navi32 aumentam o VRF para 192KB, enquanto o Navi33 e o Phoenix ainda têm 128 KB;
- Os chips em forma de chiplets terão um arquivo de registro de vetores 50% maior que os chips RDNA1/2, enquanto que os chips monolíticos terão o mesmo tamanho de 128KB, e isso visa otimizar a relação de performance por área, além é claro de entregar mais desempenho nos chips maiores.
3) RDNA3 usará apenas o motor geométrico NGG, ou seja, não será compatível com códigos GFX9 (acaba-se código legado das Polaris/Vega);
- Meio que autoexplicativo, mas enquanto que as RDNA1 e 2 permitiam a execução de um motor geométrico típico deles (NGG), eles também executavam um modo de compatibilidade das GCN, que entregava menos desempenho ao custo de maior compatibilidade. Esta decisão pode acarretar em problemas ou incompatibilidades com jogos mais/muito antigos. Segundo os documentos do RDNA1, seu processador de geometria entrega 25% mais desempenho por clock que o modo de funcionamento GCN, então essa mudança visa um ganho bem expressivo nesta parte do processamento.
4) Suporte à WMMA (Wave Matrix Multiply-Accumulate), com aceleração de INT8, FP16 e BF16. O MFMA (Matrix Fused Multiply-Add) do CDNA não está presente;
- Ter suporte a acelerar estas instruções de baixa precisão implica em um GPGPU mais rápido, e à utilização de algoritmos computacionais voltados à IA, ML e afins. Alguns jogos podem futuramente se beneficiar disso, mas à curto prazo tais precisões podem ser utilizadas em cálculos de upscale, reconstrução e denoise (ou seja, RTRT e FSR, por exemplo).
5) Display Port 2.1, suporte à UHBR13.5, UHBR20 e Encode de AV1;
- O DP2.1 fica claro que garante uma maior vazão de dados em altas resoluções, portanto 120Hz/120FPS em 8K full-chroma (nada de subsampling como ocorre nas RTX 4000). Quanto às outras siglas, Ultra-High BitRate de 54Gbps e 80Gbps através do cabo DP e, é claro, encode via hardware em AV1.
6) Novas instruções para agilizar RTRT, inclusive algumas que poderão ser RT-Traversal (BVH). Mais informações aqui;
- Basicamente, algumas dessas novas instruções visam aliviar a carga nos VGPR (Registrador de Propósito Geral de Vetores), fazendo com que a execução do RTRT em paralelo com a execução do jogo tenha seu impacto reduzido no consumo de desempenho.
7) InfCache com menor latência/maior largura de banda, muito mais flexível e agora endereçável para os desenvolvedores (mais informações aqui);
- Além de uma organização interna mais granular (rendendo-lhe uma maior largura de banda e/ou menor latência), o InfCache agora é endereçável, aka, agora será possível para os desenvolvedores acessar e/ou controlar o que é lido e/ou escrito nesta cache, a nível de instrução. Isto abre um leque enorme de possibilidades e otimizações.
8) Dobro de cache L0/L1, SW Instruction scoreboard, Ray Arbiter (não se sabe o que ambos fazem);
- Dobrar a cache mais próxima dos ALUs impulsiona a velocidade de execução, então não tem muito o que falar aqui, já quanto aos dois demais é apenas um chute o que vou dizer pois não se sabe nada de concreto sobre eles: O SWIS visa manter/atualizar um placar de instruções para garantir que sempre o menor tempo / rota mais otimizada seja executada, onde esta tabela é gerada/atualizada via software (ou seja, é uma tabela dinâmica que varia de acordo com o software em execução); Já o árbitro de raios é algo que implica em um organizador de coerência de raios para o RTRT. Existe uma patente para o SWIS, inclusive.
9) Por fim, OREO (Opaque Random Export Order). Mais informações aqui (https://www.angstronomics.com/i/68134041/oreo).
- Aqui vou usar a explicação do Angstronomics: O OREO é apenas uma das muitas técnicas de economia de área. Com gfx10, os shaders de pixel são executados fora de ordem, onde as saídas vão para um Buffer de Reordenação antes de passar para o resto do pipeline em ordem. Com o OREO [no gfx11], a próxima etapa (blend) agora pode receber e executar operações em qualquer ordem e exportar para a próxima etapa em ordem. Assim, o ROB pode ser substituído por um skid buffer muito menor, economizando área.
---
... Esse comentário aqui resume bem o RDNA3 em relação às outras duas uArchs:
Bem, esse meu comentário é basicamente uma explicação opinativa superficial mas "simples" sobre essas mudanças a nível de arquitetura, e embora sugira uma mudança enorme (que realmente é) na prática os resultados podem não ser na mesma proporção. Como o @XesqueVara e o @DiogoDX disseram, é uma mudança muito brusca a nível de arquitetura e isso pode tanto significar muito desempenho como apenas uma otimização de execução/funcionamento dela, e é por isso que tem-se ILP e Clocks a mais acima disso tudo que foi dito, deixando qualquer previsão bem meio que difícil de se dar.
Podemos estar olhando para um salto de otimização de arquitetura com um ganho oriundo disso, como foi o caso do Zen+ para o Zen2, ou seja, o verdadeiro potencial dessa mudança ainda esta por vir (RDNA4 será para o RDNA3 o que o Zen3 foi para o Zen2). Mas não vou pensar assim, vou apenas esperar o dia 3 e ver o que vem por ai, 50% mais performance por watt é o mínimo que espero :3
---
Edit: Vale lembrar @Alberth-OC que o RDNA3 quebra com a compatibilidade de código do GCN, é uma uArch nova, então finalmente os drivers estarão livre de qualquer resquício das Vega/Polaris, e isso implica em ser mais limpos e feitos do zero. Claro que pode ser algo ruim (vide AGESAs de toda mudança radical no Zen) ou não (sem código legado, sem problemas legado), afinal estamos falando da AMD no lado software, logo é torcer pelo melhor xD
Última edição:
Isso pode dar ruim para a RDNA2?Edit: Vale lembrar @Alberth-OC que o RDNA3 quebra com a compatibilidade de código do GCN, é uma uArch nova, então finalmente os drivers estarão livre de qualquer resquício das Vega/Polaris, e isso implica em ser mais limpos e feitos do zero. Claro que pode ser algo ruim (vide AGESAs de toda mudança radical no Zen) ou não (sem código legado, sem problemas legado), afinal estamos falando da AMD no lado software, logo é torcer pelo melhor xD
Não, na verdade isso vai dar ruim para o time de software da AMD, pois implica que o driver terá que dar suporte a três arquiteturas distintas (GCN4/5, RDNA1/2 e RDNA3), logo mais trabalho e drivers maiores (antes eram apenas duas). Quando o atual Catalyst deixar de oferecer suporte ao GCN é que veremos um real avanço e progresso, mas vale lembrar que não é todo GCN que é suportado, apenas as Vega (GCN5) e Polaris (GCN4) ainda estão sendo mantidos no Adrenalin, e até onde se vê esse suporte demorará a ser deixado de lado (afinal de contas a AMD ainda lança APUs com Vega como suas iGPU).Isso pode dar ruim para a RDNA2?
No caso, para as placas já lançadas essa mudança não implica em nada grave, só naquela redução de dedicação à extração de desempenho, só mantendo-as com resolução de problemas e bug-fixes, novidades e ganhos virão apenas com/para as RDNA3, como sempre aconteceu (e como estas RDNA têm blocos em comum, ainda haverá ganhos indiretos).
Não sei os termos técnicos, mas li que quem usa VR (especialmente o Quest 2) tem muito problema com placas AMD, algo do encoder da AMD ser muito ruim. Espero que resolvam isso nesta nova série. Ter uma placa dessas e não aproveitar VR é um desperdício enorme.

 forums.guru3d.com
forums.guru3d.com
AMD AMF and GPU Encoding Issues and Discussion (notably for VR)
I didn't think much of a GPU encoder prior to getting a Quest 2 VR headset. It uses the GPU encoder, and I've ran into too many issues with encoding...
O Encoder/Decoder da AMD não é ruim, briga com o da NVIDIA de igual-para-igual no H264 (RDNA1+) e também no HEVC (RDNA2+), e agora na RDNA3 virá o AV1.Não sei os termos técnicos, mas li que quem usa VR (especialmente o Quest 2) tem muito problema com placas AMD, algo do encoder da AMD ser muito ruim. Espero que resolvam isso nesta nova série. Ter uma placa dessas e não aproveitar VR é um desperdício enorme.
AMD AMF and GPU Encoding Issues and Discussion (notably for VR)
I didn't think much of a GPU encoder prior to getting a Quest 2 VR headset. It uses the GPU encoder, and I've ran into too many issues with encoding...
O problema não é o hardware, aliás o problema da AMD não é o hardware tem três gerações já... o problema é o SOFTWARE.
O AMF até hoje é uma salada de problemas e o suporte além dos programas mais conhecidos (como OBS) é praticamente nulo. Mesmo sendo open-souce, a comunidade não consegue colocar ele "nos trilhos" e por causa disso o desenvolvedor fica com toda a responsabilidade de "fazer funcionar" (e é aqui que programas de terceiros se complicam), além de que a documentação do AMF também não ajuda muito.
Some isso ao fato de que muitos desenvolvedores se acomodam com o suporte da NVIDIA e temos esse caos, ainda mais na área de VR que é um nicho (não tão pequeno quanto antes, mas ainda assim um nicho). Veja na explicação do autor do tópico, onde ele diz que "Enviar dados brutos por cabos de exibição não é o futuro para o VR, e a codificação de GPU parece estar aqui para ficar por um tempo", e mesmo estando correto o DP2.1 proporcionará passar a stream sem compressão e será um workaround para esses problemas ao menos nas RDNA3 (isso se o Dev permitir passthrough).
A AMD precisa mesmo, e muito, de organizar seu time de software e urgentemente colocar o driver nos trilhos, além de estender o suporte a parceiros de forma mais direta, pois mesmo no streaming que já é um mercado grande a AMD não se importa em corrigir seu software (a evolução do VCE para o AMF foi muito boa, mas tem muito chão ainda pela frente).
Última edição:
Uhum, posso sim :3
1) Mudanças no WGP: Cada CU agora faz dupla-entrada FP32 (2xSPs);
- O WGP (Processador de grupo de Trabalho) unia dois CU (Unidades Computacionais) e agora ele foi dobrado novamente, mas não existe mais como essa divisão, não existe mais CU, é apenas WGP (como o item 3 diz, todas as dependências/arquitetura legado da GFX9 foram deixadas para trás). Agora cada grupo de trabalho é composto por 256 Stream Processors (ALUs/FP32) que compartilham um só LDS e caches (instrução de shaders e de dados escalares). Na prática, somado ao Paralelismo a nível de instrução, vai permitir uma maior vazão de dados, agilizando seu processamento.
2) Navi31 e Navi32 aumentam o VRF para 192KB, enquanto o Navi33 e o Phoenix ainda têm 128 KB;
- Os chips em forma de chiplets terão um arquivo de registro de vetores 50% maior que os chips RDNA1/2, enquanto que os chips monolíticos terão o mesmo tamanho de 128KB, e isso visa otimizar a relação de performance por área, além é claro de entregar mais desempenho nos chips maiores.
3) RDNA3 usará apenas o motor geométrico NGG, ou seja, não será compatível com códigos GFX9 (acaba-se código legado das Polaris/Vega);
- Meio que autoexplicativo, mas enquanto que as RDNA1 e 2 permitiam a execução de um motor geométrico típico deles (NGG), eles também executavam um modo de compatibilidade das GCN, que entregava menos desempenho ao custo de maior compatibilidade. Esta decisão pode acarretar em problemas ou incompatibilidades com jogos mais/muito antigos. Segundo os documentos do RDNA1, seu processador de geometria entrega 25% mais desempenho por clock que o modo de funcionamento GCN, então essa mudança visa um ganho bem expressivo nesta parte do processamento.
4) Suporte à WMMA (Wave Matrix Multiply-Accumulate), com aceleração de INT8, FP16 e BF16. O MFMA (Matrix Fused Multiply-Add) do CDNA não está presente;
- Ter suporte a acelerar estas instruções de baixa precisão implica em um GPGPU mais rápido, e à utilização de algoritmos computacionais voltados à IA, ML e afins. Alguns jogos podem futuramente se beneficiar disso, mas à curto prazo tais precisões podem ser utilizadas em cálculos de upscale, reconstrução e denoise (ou seja, RTRT e FSR, por exemplo).
5) Display Port 2.1, suporte à UHBR13.5, UHBR20 e Encode de AV1;
- O DP2.1 fica claro que garante uma maior vazão de dados em altas resoluções, portanto 120Hz/120FPS em 8K full-chroma (nada de subsampling como ocorre nas RTX 4000). Quanto às outras siglas, Ultra-High BitRate de 54Gbps e 80Gbps através do cabo DP e, é claro, encode via hardware em AV1.
6) Novas instruções para agilizar RTRT, inclusive algumas que poderão ser RT-Traversal (BVH). Mais informações aqui;
- Basicamente, algumas dessas novas instruções visam aliviar a carga nos VGPR (Registrador de Propósito Geral de Vetores), fazendo com que a execução do RTRT em paralelo com a execução do jogo tenha seu impacto reduzido no consumo de desempenho.
7) InfCache com menor latência/maior largura de banda, muito mais flexível e agora endereçável para os desenvolvedores (mais informações aqui);
- Além de uma organização interna mais granular (rendendo-lhe uma maior largura de banda e/ou menor latência), o InfCache agora é endereçável, aka, agora será possível para os desenvolvedores acessar e/ou controlar o que é lido e/ou escrito nesta cache, a nível de instrução. Isto abre um leque enorme de possibilidades e otimizações.
8) Dobro de cache L0/L1, SW Instruction scoreboard, Ray Arbiter (não se sabe o que ambos fazem);
- Dobrar a cache mais próxima dos ALUs impulsiona a velocidade de execução, então não tem muito o que falar aqui, já quanto aos dois demais é apenas um chute o que vou dizer pois não se sabe nada de concreto sobre eles: O SWIS visa manter/atualizar um placar de instruções para garantir que sempre o menor tempo / rota mais otimizada seja executada, onde esta tabela é gerada/atualizada via software (ou seja, é uma tabela dinâmica que varia de acordo com o software em execução); Já o árbitro de raios é algo que implica em um organizador de coerência de raios para o RTRT. Existe uma patente para o SWIS, inclusive.
9) Por fim, OREO (Opaque Random Export Order). Mais informações aqui (https://www.angstronomics.com/i/68134041/oreo).
- Aqui vou usar a explicação do Angstronomics: O OREO é apenas uma das muitas técnicas de economia de área. Com gfx10, os shaders de pixel são executados fora de ordem, onde as saídas vão para um Buffer de Reordenação antes de passar para o resto do pipeline em ordem. Com o OREO [no gfx11], a próxima etapa (blend) agora pode receber e executar operações em qualquer ordem e exportar para a próxima etapa em ordem. Assim, o ROB pode ser substituído por um skid buffer muito menor, economizando área.
---
... Esse comentário aqui resume bem o RDNA3 em relação às outras duas uArchs:
Bem, esse meu comentário é basicamente uma explicação opinativa superficial mas "simples" sobre essas mudanças a nível de arquitetura, e embora sugira uma mudança enorme (que realmente é) na prática os resultados podem não ser na mesma proporção. Como o @XesqueVara e o @DiogoDX disseram, é uma mudança muito brusca a nível de arquitetura e isso pode tanto significar muito desempenho como apenas uma otimização de execução/funcionamento dela, e é por isso que tem-se ILP e Clocks a mais acima disso tudo que foi dito, deixando qualquer previsão bem meio que difícil de se dar.
Podemos estar olhando para um salto de otimização de arquitetura com um ganho oriundo disso, como foi o caso do Zen+ para o Zen2, ou seja, o verdadeiro potencial dessa mudança ainda esta por vir (RDNA4 será para o RDNA3 o que o Zen3 foi para o Zen2). Mas não vou pensar assim, vou apenas esperar o dia 3 e ver o que vem por ai, 50% mais performance por watt é o mínimo que espero :3
---
Edit: Vale lembrar @Alberth-OC que o RDNA3 quebra com a compatibilidade de código do GCN, é uma uArch nova, então finalmente os drivers estarão livre de qualquer resquício das Vega/Polaris, e isso implica em ser mais limpos e feitos do zero. Claro que pode ser algo ruim (vide AGESAs de toda mudança radical no Zen) ou não (sem código legado, sem problemas legado), afinal estamos falando da AMD no lado software, logo é torcer pelo melhor xD
Muito obrigado por toda a explicação.

Será que teremos um concorrente para o DLSS 3.0?

 wccftech.com
wccftech.com
Será?
Ou?


AMD Confirms Radeon RX 7000 "RDNA 3" GPUs To Include New Features Targeting High-Resolution & High Frame-Rate Gaming
AMD's CEO, Dr. Lisa Su, confirmed that their Radeon RX 7000 "RDNA 3" GPUs will include brand new gaming features.
Será?
Ou?
Última edição:
PowerColor provoca a próxima série Radeon RX 7000 Devil.
O Diabo se transformará em muitas formas”
A empresa é a primeira a mostrar um teaser para a nova GPU RDNA3.O que estamos vendo é provavelmente a primeira GPU RDNA3 personalizada. Há um grande logotipo PowerColor Devil iluminado por LEDs atrás de um elemento translúcido. Um design de cobertura poligonal nunca foi usado pela PowerColor antes.

Pode-se adivinhar que esta é a frente do cartão, o que significa que não há fãs no próprio cartão. Esta pode ser a primeira placa PowerColor refrigerada por uma solução tudo-em-um com radiador externo.

A série RX 7000 será anunciada amanhã pela AMD. A empresa não confirmou quantos cartões serão revelados, nem se os parceiros do conselho também poderão exibir seus designs. No entanto, o tweet da PowerColor, que na verdade é um anúncio do sorteio do Diabo (um cartão?), indica que esse será o caso.
Fonte: Power Color
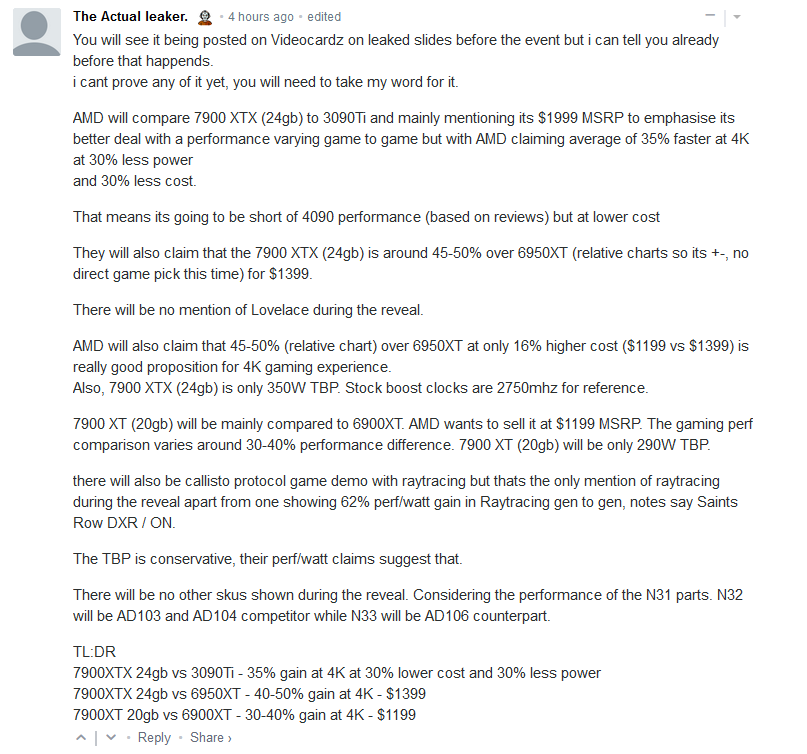
Eu creio que seria um tiro no pé a AMD comparar com a 3090Ti sem nem ao menos citar a 4090, afinal de contas já faz uns 20 dias que a Lovelace lançou, isso soaria como um desespero do tipo "olha, dessa da geração passada eu ganho", só para justificar o aumento de preço =/
---
PowerColor dando um tease da sua placa RedDevil:

PowerColor teases upcoming Radeon RX 7000 Devil series - VideoCardz.com
“The Devil will morph into many shapes” The company is first to show a teaser for the new RDNA3 GPU. What we are looking at is probably the first custom RDNA3 GPU. There is a large PowerColor Devil logo illuminated by LEDs behind a translucent element. Such a polygonal shroud design has never...
 videocardz.com
videocardz.com
EDIT: O @Cata chegou antes de mim. Minha opinião, baseado nessa imagem: Está feia que dói xD
Última edição:
Vai ser liquid cooling Tho, então tá safe.Eu creio que seria um tiro no pé a AMD comparar com a 3090Ti sem nem ao menos citar a 4090Ti, afinal de contas já faz uns 20 dias que a Lovelace lançou, isso soaria como um desespero do tipo "olha, dessa da geração passada eu ganho", só para justificar o aumento de preço =/
---
PowerColor dando um tease da sua placa RedDevil:
PowerColor teases upcoming Radeon RX 7000 Devil series - VideoCardz.com
“The Devil will morph into many shapes” The company is first to show a teaser for the new RDNA3 GPU. What we are looking at is probably the first custom RDNA3 GPU. There is a large PowerColor Devil logo illuminated by LEDs behind a translucent element. Such a polygonal shroud design has never...
EDIT: O @Cata chegou antes de mim. Minha opinião, baseado nessa imagem: Está feia que dói xD
Users who are viewing this thread
Total: 3 (membros: 0, visitantes: 3)