Ótima leitura, fui para o link original (
https://ascii.jp/elem/000/004/112/4112875/ ), o qual ele diz não estar mais online (mas aqui acessou normalmente), e lá tem muita informação boa, que vou entrar em detalhes daqui a pouco, mas enquanto eu lia o ASCII o tomshardware veio e fez uma análise também, como você bem linkou... Esse post vai ser grande, já estou imaginando xD
Bem, demorei tanto escrevendo que muitos pontos que eu tocaria foram apresentados pelo Tom's, mas ainda tenho o que falar:
- Yusuke Ohara disse que, ao jogar os controladores e InfCache no MCD, a AMD economizou 20% do die do GCD, e que a escolha pelo N6 foi porque
"nós [AMD] não estamos mais fazendo novos designs em 7nm, logo escolhemos o N6" (Sam Naffziger). Ele também disse que o custo de um waffer em 5nm é 70% mais caro que em 7nm (17k por bolacha, contra 10k em 7nm);
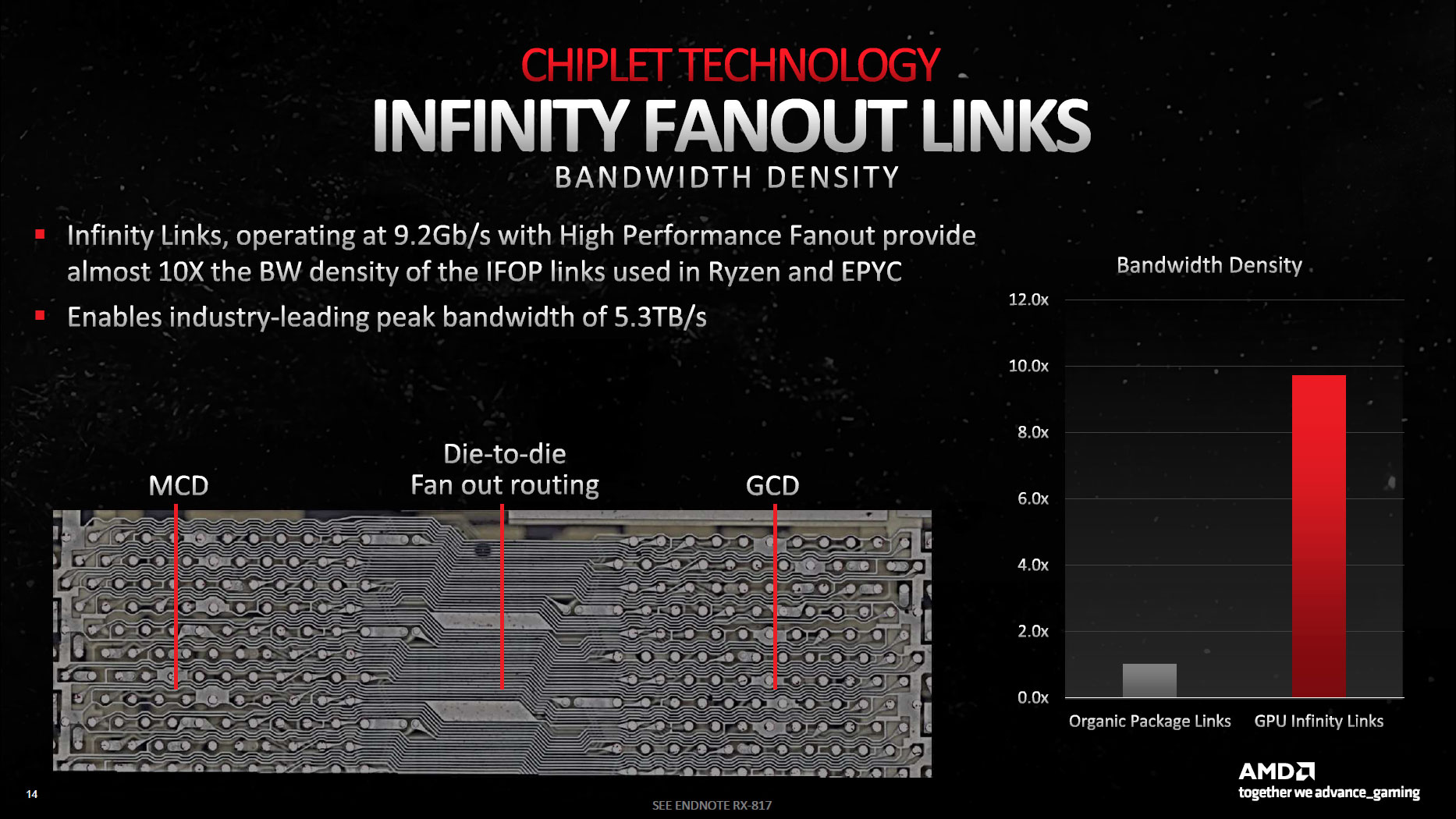
- O InfinityLink ganha um slide, e nele é dito que a conexão suporta uma transferência máxima de 9,2 Gbps por IFOP link, oferecendo assim os 5,3 TB/s máximos da Navi31. Interessante é o segundo slide, onde é informado que todos os links IFOP combinados
entregam 3,5 TB/s de largura de banda efetiva (ou seja, InfinityCache + hit-rate + GDDR6), custando apenas 5% do total do consumo da placa (logo ~18W). Ou seja, a AMD conseguiu manter o mesmo gasto energético da RDNA2 aumentando a largura de banda efetiva de 1,6 TB/s para 3,5 TB/s (2,2x mais);
- Jarred Walton veio com um número estranho, mas como ele tem acesso aos documentos e à AMD... Que número? O InfinityFabric da Navi31 custar 0,4 pJ/bit para movimentar os dados off-die, quando a Navi21 gasta 1,3 pJ/bit on-die. Creio que ele se equivocou, e os 0,4 pJ/bit refere-se à comunicação on-die da Navi31. Pela informação dos slides da AMD o gasto está mais para algo entre 0,6 e 0,9 pJ/bit;
-
Comparando com meu post anterior, percebe-se que sim, a AMD está utilizando uma versão modificada do GLink 2.3LL, pois o link da GUC oferece até 17 Gbps por link enquanto que o InfinityLink consegue 9,2 Gbps. Antes que perguntem,
esta é a fonte que confirma a utilização do GLink na RDNA3;
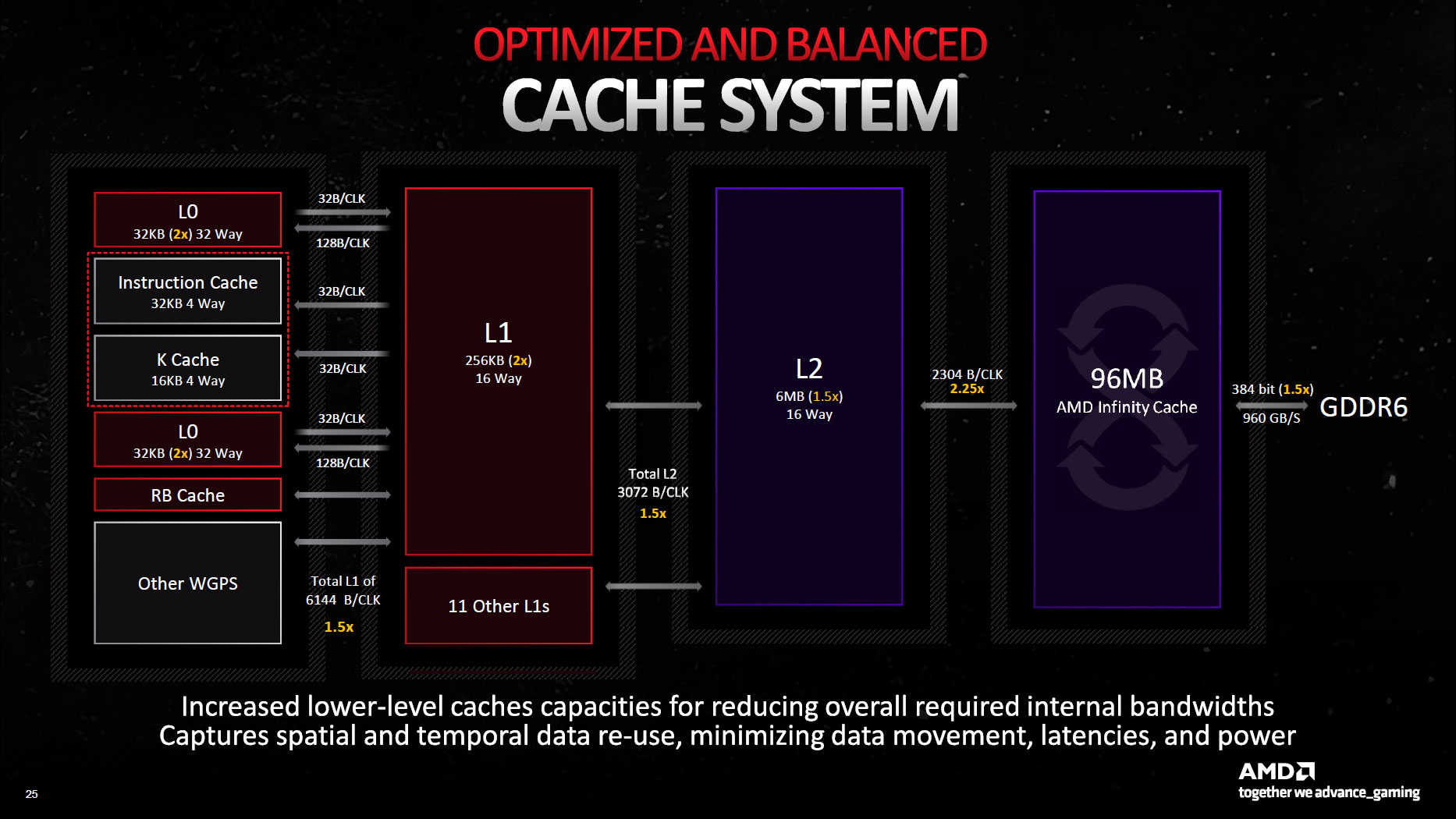
- Por fim, o mapa da hierarquia de memórias (caches) da RDNA3, onde podemos ver que houve ganhos na largura de banda de todos os lados, onde da L0 para a L1 e da L1para a L2 aumentaram em 50% cada, e da L2 para a LLC (InfCache) foi um aumento de 225% (alcançando os 5,3 TB/s). Como fica claro, a velocidade é síncrona com o clock, logo escalará com OC.
---
Agora que falei da parte de memória e chiplet, é hora de me aprofundar na mudança da arquitetura, mas ficará para depois, hoje ainda posto
")
PS: Por enquanto deixo esta informação 'interessante' aqui:


 Outros tentaram botar na opção de retirar na loja porque não queriam pagar frete e perderam kkkkkk, mas alguns finalizaram a compra sim, agora é ver se vão honrar
Outros tentaram botar na opção de retirar na loja porque não queriam pagar frete e perderam kkkkkk, mas alguns finalizaram a compra sim, agora é ver se vão honrar