Estava aqui conversando com meus neurônios e me encucando com o consumo da intercomunicação do RDNA3, até que com a apresentação dos GENOA vi um slide e consegui tirar minha dúvida, mas primeiro vou par um slide antigo, da RDNA2:

Informação importante: Gasto energético para mover um dado de/para o Infinity Cache, que é de 1,3 pJ/bit. Certo... e o que esse número significa? Sabendo que 1pJ/bit equivale a 1 mW/Gbps, temos (na 6900XT):
- 1664GBps * 0,0013 W/Gbps = 2,16W * 8 = 17,30W
Certo, e onde está o slide do EPYC? Aqui:
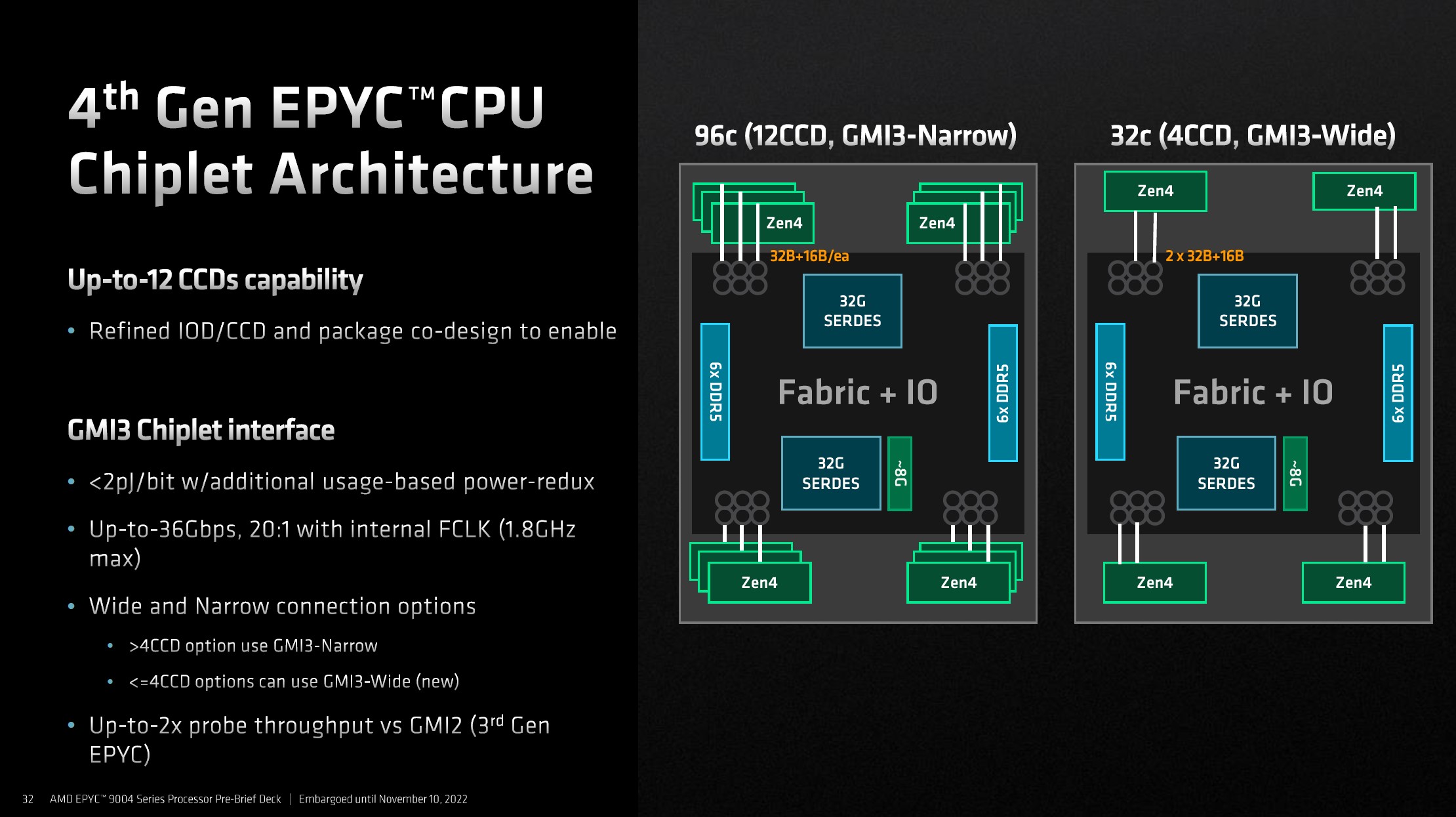
A comunicação do chiplet com o IOD dos EPYCs aparentemente utilizam o mesmo protocolo das RDNA3, então é bem provável que o custo para movimentar dados entre ambas seja o mesmo. Por que eu digo que ambos utilizam o mesmo protocolo? Porque esse documento diz que essa intercomunicação também é a da RDNA3:

Interessante não? Bem, voltando, olhem para quanto caiu o custo de movimentação de dados intra-die: De 1,3pJ/bit para 0,3pJ/bit, então agora temos o valor inter-die e intra-die, e isso possibilita...
- 5300GBps * 0,0018 W/Gbps = 2,65W * 8 = 76,32W
Ou seja, enquanto que a RDNA2 gastava ~17W para ler/escrever dados no InfinityCache a uma velocidade de ~1,5TB/s, a RDNA3 gasta ~76W para ler/escrever nessa mesma LLC a uma velocidade de 5,3TB/s. Logo realmente um clock maior nos shaders vai elevar esse consumo, mas não tanto quanto imaginava (~3GHz shader clock = ~90W InfLink, mas não chegará nisso pois saturaria o limite*** da intercomunicação, portanto o consumo máximo seria de ~79W, ~88W no pior dos casos).
---
OBS1: Interessante saber que essa intercomunicação tem um limite atual de 912,5 GB/s por PHY, o que dá 5,475 TB/s de largura de banda máxima na 7900XTX, ou seja, a AMD já deixou a largura de banda na sua topo de linha praticamente no máximo;
OBS2: Coloquei a eficiência em 1,8pJ/bit pois é o valor do custo do Infinity Fabric (1,5pJ/bit) somado com 0,3pJ, e que fica abaixo dos 2pJ/bit informado nos GENOA, então é um chute bem realista (apesar de ter quem acredite que é o valor é de 2pJ/bit mesmo), logo todo esse consumo é algo aproximado e só teremos certeza quando a AMD soltar um documento ou falar explicitamente.
OBS3: Aqui uma tabela comparativa de custo de movimentação de dados em outras tecnologias/protocolos (o EMIB está mais para 0,5 que 0,3):

Informação importante: Gasto energético para mover um dado de/para o Infinity Cache, que é de 1,3 pJ/bit. Certo... e o que esse número significa? Sabendo que 1pJ/bit equivale a 1 mW/Gbps, temos (na 6900XT):
- 1664GBps * 0,0013 W/Gbps = 2,16W * 8 = 17,30W
Certo, e onde está o slide do EPYC? Aqui:
A comunicação do chiplet com o IOD dos EPYCs aparentemente utilizam o mesmo protocolo das RDNA3, então é bem provável que o custo para movimentar dados entre ambas seja o mesmo. Por que eu digo que ambos utilizam o mesmo protocolo? Porque esse documento diz que essa intercomunicação também é a da RDNA3:
Interessante não? Bem, voltando, olhem para quanto caiu o custo de movimentação de dados intra-die: De 1,3pJ/bit para 0,3pJ/bit, então agora temos o valor inter-die e intra-die, e isso possibilita...
- 5300GBps * 0,0018 W/Gbps = 2,65W * 8 = 76,32W
Ou seja, enquanto que a RDNA2 gastava ~17W para ler/escrever dados no InfinityCache a uma velocidade de ~1,5TB/s, a RDNA3 gasta ~76W para ler/escrever nessa mesma LLC a uma velocidade de 5,3TB/s. Logo realmente um clock maior nos shaders vai elevar esse consumo, mas não tanto quanto imaginava (~3GHz shader clock = ~90W InfLink, mas não chegará nisso pois saturaria o limite*** da intercomunicação, portanto o consumo máximo seria de ~79W, ~88W no pior dos casos).
---
OBS1: Interessante saber que essa intercomunicação tem um limite atual de 912,5 GB/s por PHY, o que dá 5,475 TB/s de largura de banda máxima na 7900XTX, ou seja, a AMD já deixou a largura de banda na sua topo de linha praticamente no máximo;
OBS2: Coloquei a eficiência em 1,8pJ/bit pois é o valor do custo do Infinity Fabric (1,5pJ/bit) somado com 0,3pJ, e que fica abaixo dos 2pJ/bit informado nos GENOA, então é um chute bem realista (apesar de ter quem acredite que é o valor é de 2pJ/bit mesmo), logo todo esse consumo é algo aproximado e só teremos certeza quando a AMD soltar um documento ou falar explicitamente.
OBS3: Aqui uma tabela comparativa de custo de movimentação de dados em outras tecnologias/protocolos (o EMIB está mais para 0,5 que 0,3):








